

Mai 2024 restera une date marquante dans l'histoire du référencement naturel. La fuite de plus de 2 500 documents internes de Google a levé le voile sur les mécanismes intimes du moteur de recherche le plus utilisé au monde. Cette documentation technique, comportant plus de 14 000 attributs, vient confirmer, préciser et parfois bousculer des années d'observations empiriques des professionnels du référencement.
Ces révélations s'inscrivent dans la continuité d'autres sources d'information majeures : le leak du Project Veritas en 2019, qui avait déjà fourni quelques documents techniques précieux, et surtout les transcriptions du procès antitrust opposant Google au département de la Justice américaine en 2023. Ces témoignages sous serment d'ingénieurs de Google avaient notamment mis en lumière l'importance cruciale des données comportementales des utilisateurs dans le classement.
La fuite de 2024 va beaucoup plus loin. En donnant accès à la documentation technique de l'API Content Warehouse de Google, elle révèle l'architecture complète du moteur de recherche : des systèmes d'indexation aux algorithmes de classement, en passant par les mécanismes d'évaluation de la qualité. Pour la première fois, nous disposons d'une vue précise sur la manière dont Google organise ses données, les traite et les exploite pour générer ses résultats de recherche.
Le fonctionnement du moteur en trois temps
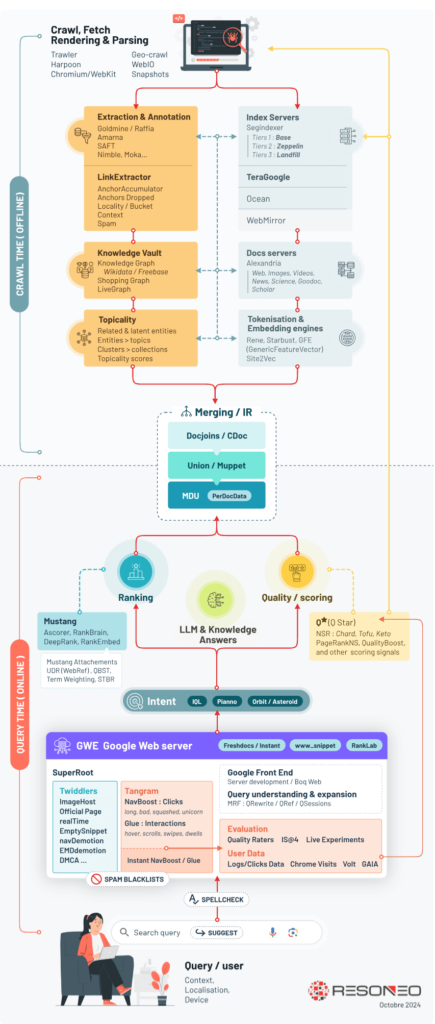
L'analyse des documents révèle une architecture en trois phases distinctes, que nous avons synthétisée dans une infographie sur le fonctionnement de Google Search d'après le Google Leak. Cette organisation permet à Google d'allier la profondeur de l'analyse à la rapidité de réponse nécessaire pour servir des milliards de requêtes quotidiennes.
Le temps du crawl : la phase off-line
Tout commence avec Trawler, le système principal de crawling qui explore et récupère les pages web. Les documents révèlent l'existence d'un nouveau composant, WebIO, apparu en 2023 pour optimiser la charge du crawl. Ce système mesure avec une granularité extrême - jusqu'à la minute près - chaque connexion sortante, témoignant de l'attention portée par Google à la gestion de ses ressources.
Une fois récupérées, les pages sont réparties entre trois niveaux d'index aux noms évocateurs : Base, Zeppelins et Landfill. Base, stocké en mémoire vive, accueille les pages les plus importantes. Zeppelins, sur disques SSD, héberge les contenus intermédiaires, tandis que Landfill (littéralement "décharge") stocke sur disques durs classiques la grande majorité des pages. Cette hiérarchisation influence jusqu'aux liens : les documents révèlent que les backlinks provenant de sites dans Landfill sont automatiquement considérés comme de faible qualité !
En parallèle s'activent de puissants systèmes d'analyse comme Goldmine et Raffia, véritables usines à metadata qui décortiquent chaque aspect des pages. SAFT (Structured Annotation Framework and Toolkit) cartographie les relations sémantiques, pendant que site2vec - cousin méconnu de word2vec - évalue la cohérence thématique globale des sites.
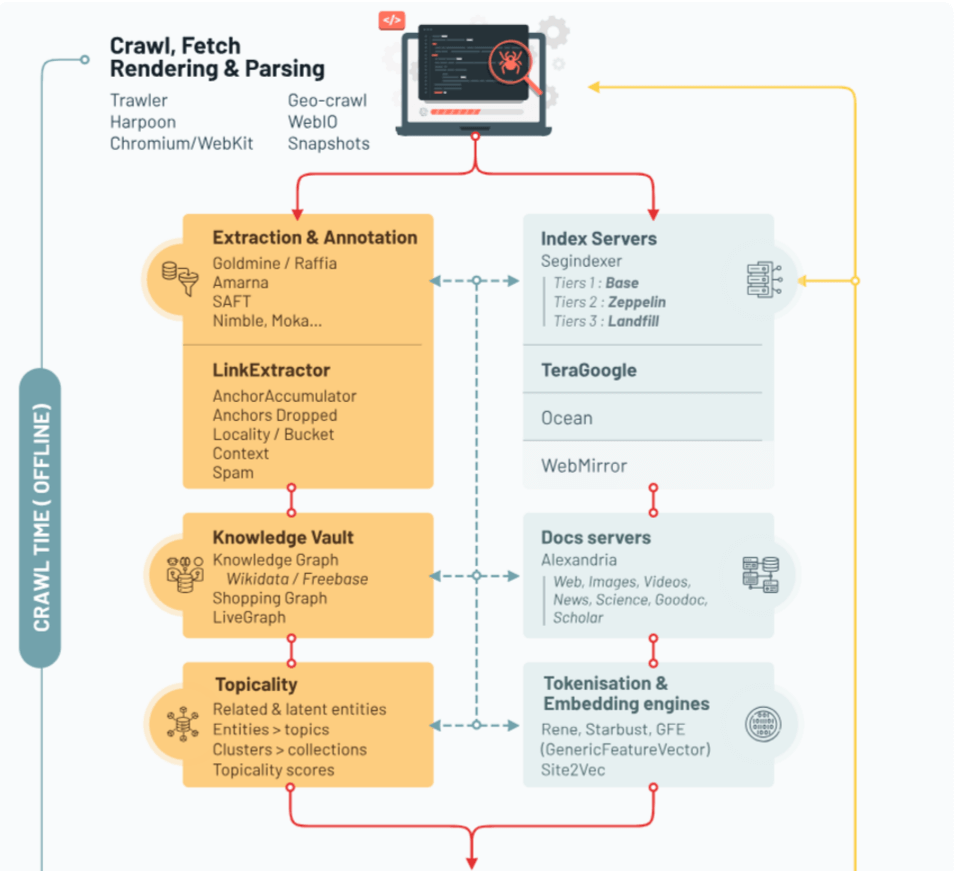
La couche intermédiaire : le merging et l'information retrieval
Entre l'indexation et le temps réel se trouve une couche cruciale dont le rôle était jusqu'ici méconnu : les systèmes de fusion (merging) et de récupération d'information. Au cœur de ce dispositif, Union/Muppet, un composant stratégique. Son rôle ? Préparer les données indexées pour leur utilisation en temps réel.
Le temps de la requête : la phase real-time
Lorsqu'un utilisateur lance une recherche, une impressionnante chaîne de traitement s'active. QRewrite et ses composants satellites (QRef, QBST, IQL) interprètent l'intention de recherche. Les grands algorithmes de ranking comme DeepRank établissent un premier classement, rapidement affiné par NavBoost et Glue qui analysent les comportements des utilisateurs. Un détail savoureux : Google a même créé un score baptisé "clickMagnetScore" pour détecter les titres putaclic qui attirent les clics mais génèrent des retours rapides à la page de résultats !
Enfin, les twiddlers (plus d'une centaine aujourd'hui) ajustent finement le positionnement avant que Tangram - anciennement baptisé Tetris - n'assemble la page finale. Le choix des snippets peut même être modifié à la dernière seconde par SnippetBrain si le système estime pouvoir faire mieux que la suggestion initiale de Muppet.
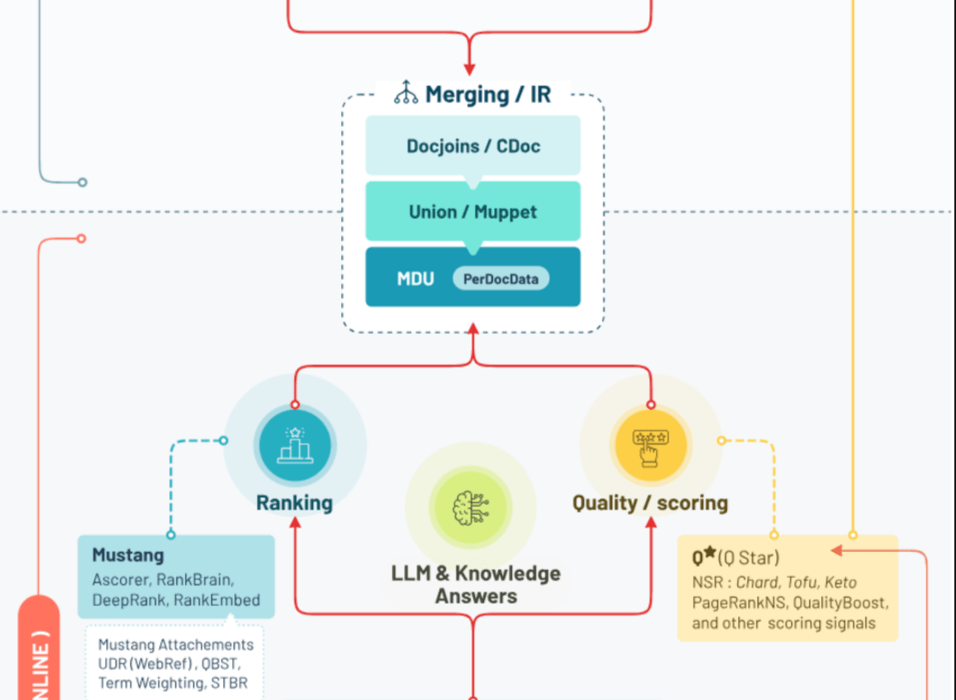
Les grandes révélations
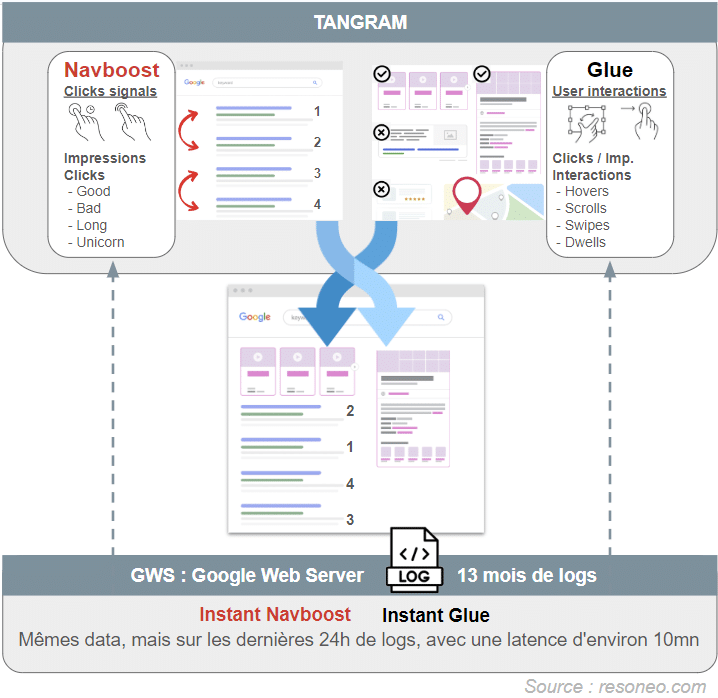
Dans l'œil de Google : comment vos clics façonnent les résultats
Vous pensiez que vos interactions avec les résultats de recherche passaient inaperçues ? Détrompez-vous ! Les documents fuités révèlent un système sophistiqué de surveillance et d'analyse de nos comportements, avec deux acteurs principaux : NavBoost et Glue.
NavBoost, c'est un peu comme un système de votes : chaque clic sur un résultat compte comme un vote pour cette page. Mais attention, Google n'est pas dupe ! Il distingue les "good clicks" (quand vous restez sur la page) des "bad clicks" (quand vous revenez immédiatement aux résultats).
Depuis 2014, Glue va encore plus loin. Il analyse tout : vos survols de souris, vos scrolls, le temps passé à examiner les extraits enrichis ou le Knowledge Graph... Même les changements de viewport sur mobile sont scrutés !
Et pour les actualités brûlantes ? Google a même créé "Instant Glue", qui analyse les comportements des dernières 24 heures avec seulement 10 minutes de délai.
Un impact massif sur le classement
Un ancien ingénieur de Google, Eric Lehman, révélait en 2019 que NavBoost à lui seul avait plus d'impact positif sur les clics que tout le reste du système de classement ! Au point que les autres équipes se plaignaient que NavBoost "volait leurs victoires"...
La leçon à retenir ? Vous devez optimiser votre contenu sous le prisme de l’engagement des utilisateurs, car au final, ce sont eux qui ont le dernier mot.
Les grands algorithmes de classement : l'IA aux commandes
Si vous imaginiez Google comme une simple calculatrice géante qui compte les mots-clés et les backlinks, préparez-vous à un choc. Les documents internes révèlent un système de classement où l'intelligence artificielle règne en maître.
RankBrain : le pionnier
Lancé en 2015, RankBrain a marqué l'entrée de Google dans l'ère du machine learning. Sa mission ? Affiner le classement des 20-30 premiers résultats, particulièrement sur les requêtes rares ou jamais vues (15% des recherches quotidiennes !). Mais RankBrain n'était que l'apéritif...
DeepRank : le boss final
Le véritable maître du classement aujourd'hui, c'est DeepRank. Basé sur BERT, il ne se contente pas d'analyser des mots-clés : il "comprend" véritablement le sens des requêtes et des contenus. Là où RankBrain joue un rôle d'arbitre final, DeepRank est impliqué beaucoup plus en profondeur dans le processus de classement.
L'IA devient incontrôlable ?
Mais il y a un revers à la médaille, révélé lors du procès antitrust de 2023. Selon Pandu Nayak, un des dirigeants de Google, DeepRank est devenu tellement complexe que même ses créateurs ont du mal à prédire son comportement. Une vraie "boîte noire" qui inquiète parfois Google en interne. Les dégâts collatéraux du récent Helpful Content Update sur des sites pourtant légitimes en sont peut-être la preuve...
Une approche holistique de la qualité
Google a développé au fil du temps une approche remarquablement sophistiquée, où chaque élément est analysé non pas isolément, mais dans son contexte global. Fini le temps où l'on pouvait optimiser page par page : Google évalue désormais la qualité sur trois niveaux (page, section, domaine) grâce à une batterie de systèmes aux noms parfois mystérieux. Des pipelines d'annotation comme Goldmine et Raffia analysent la lisibilité et la structure, pendant que SAFT cartographie les relations sémantiques.
L'armée des 16 000
Vous connaissez les guidelines des Quality Raters, ce document de 170 pages qui guide les évaluateurs de Google. Mais ce n'est que la partie émergée de l'iceberg ! Les fuites révèlent un système d'évaluation de la qualité très avancé.
Google emploierait pas moins de 16 000 évaluateurs dans le monde dont la mission est de noter la pertinence des résultats selon deux critères principaux :
- "Needs Met" : le résultat répond-il au besoin de l'utilisateur ?
- "Page Quality" : la page respecte-t-elle les standards de qualité Google ?
Leurs évaluations alimentent un indicateur appelé "IS" (Information Satisfaction), qui sert ensuite à entraîner les algorithmes de ranking.
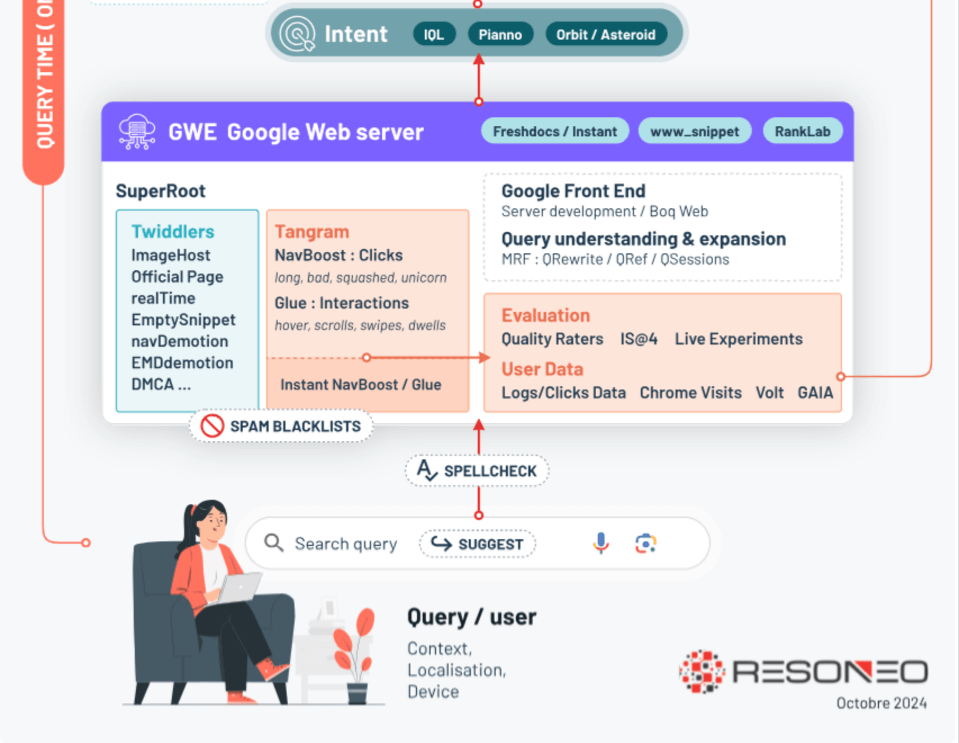
NSR et HCU : le mystère s'éclaircit
L'un des enseignements majeurs concerne le NSR (Normalized Site Rank). Ce score de qualité global évalue non seulement les pages individuelles, mais aussi des "sitechunks" (sections de sites) et des domaines entiers. Alimenté par les pipelines Goldmine et Raffia, il agrège de mystérieux signaux aux noms culinaires : Keto, Rhubarb, Tofu, et surtout le crucial ChardScore. Ce dernier apparaît dans plusieurs variantes (hoax, translated, YMYL...) pour évaluer et tenter de prédire différents aspects de la qualité. En parallèle, Site2vec évalue la cohérence thématique globale via du vector embedding. La présence de dates récentes (2022) dans la documentation et la concordance temporelle avec le déploiement du Helpful Content Update suggèrent un lien étroit entre NSR et HCU.
La "topicalité" : le nouveau Graal
Google ne se contente plus d'identifier les sujets traités : il évalue désormais la légitimité d'un site à en parler. Le leak mentionne des scores comme "siteFocusScore" et "siteRadius" qui mesurent à quel point un site est légitime sur un topic donné. C'est ce qui explique pourquoi même un excellent article sur la santé aura du mal à percer s'il est publié sur un site de recettes de cuisine...
Attention toutefois, les sites comme Le Monde, Reddit ou Amazon continueront de remonter sur de multiples thématiques, mais si sur votre site de cuisine, vous comptez parler médecine, il faudra prévoir de nombreux contenus pour prouver à Google votre autorité sur cette thématique.
Images et géolocalisation : des signaux méconnus
Le leak dévoile de multiples mécanismes d'évaluation pour les images. Par exemple, le score EQ* mesure leur qualité émotionnelle (inspiration, style de vie), tandis que TQ* évalue les aspects techniques (exposition, netteté, composition). Un enseignement pratique : même un contenu technique gagnera à être illustré, les images de qualité constituant un signal positif indépendant.
Côté local, la métrique "clickRadius50Percent" révèle comment Google détermine automatiquement la portée géographique d'une page en analysant la provenance de 50% de ses clics. Cette donnée influence ensuite la visibilité du contenu selon la localisation des utilisateurs.
Les mystérieux "Unicorn clicks"
Parmi les révélations les plus intrigantes figure la mention des "Unicorn clicks", dont le rôle exact reste mystérieux. Les utilisateurs seraient divisés en groupes (consommateurs, Dasher, Unicorn...), suggérant une possible pondération différente des interactions selon les profils. S'agirait-il des power users de Google ou au contraire des utilisateurs non connectés ? Le débat reste ouvert.
Les enseignements pratiques : adapter sa stratégie SEO
Au-delà des révélations techniques, ces fuites nous livrent des enseignements précieux pour optimiser efficacement nos contenus. Voici les principaux axes à privilégier.
Repenser l'autorité thématique
La compréhension du siteFocusScore et du siteRadius nous invite à structurer nos sites différemment. L'enjeu n'est plus simplement de produire du contenu de qualité, mais de construire une véritable cohérence thématique :
- Regroupez vos contenus en clusters thématiques clairement identifiables
- Évitez la dispersion sur des sujets trop éloignés de votre cœur d'expertise
- Si vous souhaitez aborder une nouvelle thématique, construisez progressivement votre légitimité avec un corpus substantiel de contenus
- Utilisez les techniques de clustering et de topic mapping pour identifier vos forces et faiblesses thématiques
- Et même au sein d’une page, ne digressez pas trop sou peine de vous voir disqualifié par Google
Du link building au mention building
Les contraintes révélées sur le traitement des liens (limites d'ancres, classification Base/Landfill) suggèrent quelques évolutions des stratégies de popularité :
- Privilégiez la qualité à la quantité : un backlink d'un site "Base" vaut mieux que des centaines de liens "Landfill"
- Diversifiez vos sources de liens pour éviter les seuils de saturation par domaine
- Meme sans liens, développez les mentions de vos entités de marque (marque, produits, nom de domaine, dirigeants, adresse…) : Google les analyse pour renforcer votre autorité.
- Ciblez particulièrement les sites d'actualité de qualité, expressément valorisés dans les documents
Optimiser l'engagement utilisateur
Les mécanismes de NavBoost et Glue nous rappellent l'importance cruciale des signaux comportementaux :
- Analysez finement les taux de rebond et temps de lecture par page
- Optimisez la cohérence de vos titles / descriptions, visuels avec vos contenus pour éviter l’effet déception des utilisateurs
En conclusion, ces fuites confirment l'évolution de Google vers une évaluation toujours plus holistique et contextuelle de la qualité. Le succès en SEO passe plus que jamais par une approche globale conjuguant expertise technique pointue et création de valeur réelle pour les utilisateurs, en construisant des territoires d'expertise cohérents.
Articles complémentaires :

Étude exclusive : ce que révèlent 332 millions de recherches Google

Dans les coulisses d’Abondance : retour sur un an d’évolutions

Google leak : Des milliers de documents internes révèlent les secrets de l’algorithme

NavBoost décrypté : Comment les clics utilisateurs influencent le classement Google

Mauvais classement Google : les 4 raisons selon Danny Sullivan






 Participez à notre 1ère étude sur le netlinking & les relations presse
Participez à notre 1ère étude sur le netlinking & les relations presse
 À gagner : 3 abonnements d’un an à Réacteur.com
À gagner : 3 abonnements d’un an à Réacteur.com
 Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Superbe article ! Un vrai régal à lire et relire. Merci 🙂
Bonjour, merci pour cet article passionnant. Cela donne beaucoup du crédit aux SEO qui travaillent la topical authority et les entités.
Bravo pour l’article, j’ai pas encore tout bien compris :p mais c’est super intéressant de voir le SEO sous cet angle différent.
Bonjour Joseph,
Merci pour votre message 🙂
Voici le lien vers la route API concernant le clickRadius50Percent :
https://hexdocs.pm/google_api_content_warehouse/0.4.0/GoogleApi.ContentWarehouse.V1.Model.CountryGeoLocation.html#module-attributes
Comme vous le verrez, ce n’est pas tellement plus développé, il s’agit d’une métrique relativement claire avec un intitulé relativement descriptif 😉
Bonne journée
Merci pour cet article ultra intéressant et tellement riche en information.
Remarquable et appréciable synthèse. Merci pour le travail fait.
Quelle est la source de l’info au sujet du « clickRadius50Percent » ? Je présume que le mécanisme doit être un peu moins basique qu’expliqué. Une situation observée à un moment donné (par ex. au début de la mise en ligne du contenu concerné) pouvant être trompeuse, j’imagine que c’est surtout l’évolution des résultats de ce critère qui est pris en compte par Google.
Bonjour Joseph, la source est le Google Leak 😊 Je demande à Olivier de vous apporter plus de précisions à ce sujet !