

La récente fuite de 2500 documents internes de l’équipe de recherche de Google a bouleversé le monde du SEO : tout le monde ne parle que de ça ! Mais certains ont un regard très critique face au Google Leak, c’est pourquoi Mike King, le fondateur d’iPullRank, a pris la parole pour répondre aux sceptiques.
Ce qu'il faut retenir :
- Mike King affirme que les documents apportent de véritables nouveaux éléments en plus de confirmations de pratiques SEO existantes ;
- Les documents ont été authentifiés par d’anciens employés de Google, et indirectement par la firme elle-même dans sa dernière déclaration ;
- Les documents sont au moins postérieurs à août 2023 et mentionnent des technologies récentes ;
- Cela ne doit pas vous empêcher de faire preuve de prudence et de tester vous-même les hypothèses.
Remise en contexte
La fuite de l'API Google Content Warehouse a révélé des informations sur les critères de ranking de Google. Rand Fishkin, qui a reçu ces documents début mai, a demandé à Mike King de l’aider à analyser ces 2500 documents, confirmant de nombreuses pratiques SEO et exposant de nouvelles variables utilisées par Google.
Cette fuite donne un aperçu des mécanismes internes de l'algorithme de recherche, fournissant ainsi des outils précieux pour optimiser les stratégies SEO. Si la société affirme que les documents divulgués manquent de contexte et sont obsolètes, ils confirment néanmoins que la fuite concerne bien des documents de Google.
“Nous savions déjà tout ça”
Certains internautes ont affirmé qu'ils avaient déjà connaissance de toutes les informations divulguées. Mike King réfute cette affirmation en soulignant que la communauté SEO a longtemps spéculé sur de nombreuses bonnes pratiques sans avoir de confirmation précise.
La fuite offre certes des confirmations de spéculations ou de tests, mais également des informations qui n'étaient pas disponibles auparavant, permettant une compréhension plus approfondie des systèmes de classement de Google.
“Nous devrions nous concentrer sur les clients et non sur la fuite”
Un autre argument avancé est de se concentrer uniquement sur les clients sans trop se préoccuper de la fuite de documents. King reconnaît l'importance de cette approche mais souligne que comprendre les mécanismes internes de Google permet justement de mieux servir les clients.
En connaissant les facteurs de classement, les spécialistes SEO peuvent expliquer plus précisément les variations de performance et obtenir l'adhésion des clients pour les mises en œuvre nécessaires à leur réussite sur le web.
“La fuite n’est pas réelle”
La véracité de la fuite a bien évidemment été remise en question. Mike King affirme que plusieurs sources indépendantes, y compris des anciens employés de Google (Xooglers), ont authentifié les documents. De plus, Google a indirectement validé la fuite par une déclaration officielle. Cette confirmation renforce la crédibilité des informations divulguées.
“Nous ne savons pas quel âge ont ces documents”
King souligne que les fichiers sont au moins plus récents qu’août 2023 et contiennent des références à des technologies récentes, comme les LLM. Lorsque ce code a été déployé, il contenait 2 596 fichiers, or un grand nombre de ces fichiers ne figuraient pas auparavant dans le référentiel, il s’agirait donc bien de la dernière version.
“Cela ne mentionne pas le CTR, donc ce n’est pas utilisé”
Certains ont noté l'absence de mention explicite du taux de clic (CTR) dans les documents, concluant ainsi qu'il n'est pas utilisé. King rejette cette idée en soulignant que Google est parfaitement capable de calculer le CTR en temps réel, et que l'absence de mention explicite ne signifie pas que cette métrique n'est pas prise en compte.
“Soyez prudent avec les conclusions tirées de ces informations”
Là-dessus, le fondateur d’iPullRank est parfaitement d’accord : il ne faut pas tirer de conclusions hâtives. Il propose de tester méthodiquement les hypothèses basées sur les données du Google Leak et de faire preuve de prudence. Même avec une interprétation rigoureuse, il est possible que certaines conclusions soient incorrectes.
“Cela nous détourne des discussions sur les AI Overviews”
L'hypothèse selon laquelle la fuite serait une diversion orchestrée par Google pour détourner l'attention des AI Overviews est complètement rejetée par Mike King. En effet, la fuite provient d'une mauvaise configuration de déploiement datant de mars et que les documents ont été découverts par hasard en mai, sans lien avec les discussions sur le remplacement de la SGE par les AI Overviews.
“Tout n’est pas relatif à la recherche”
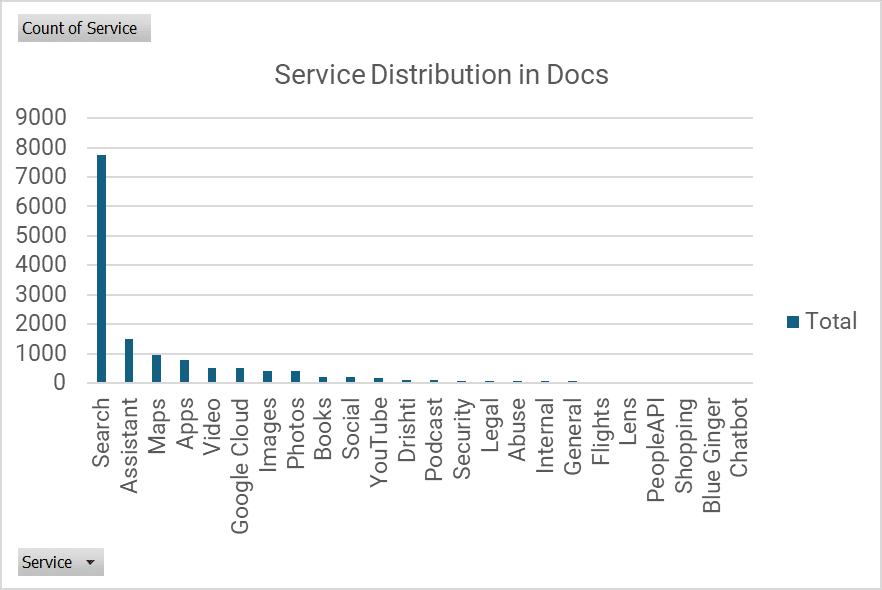
Effectivement, dans les 14 000 fonctionnalités présentes dans ces documents, seuls 8 000 sont liées à la recherche, d’après Mike King. C’est déjà un bon chiffre ; et cela n’enlève pas l’intérêt des autres informations relatives à Google Maps, aux vidéos ou encore à YouTube.
Voici la segmentation des modules :
“Ce n’est qu’une liste de variables”
Pour ceux qui voient les documents comme une simple liste de variables, King répond que chaque variable est décrite avec des détails qui révèlent le niveau de granularité avec lequel Google comprend et traite le web. Ces informations sont précieuses pour quiconque s'intéresse aux facteurs de classement.
“Cela ne changera rien à ma manière de faire du SEO”
Certains pensent que ces révélations n'impacteront pas leur stratégie SEO. Mike King insiste sur le fait que les nouvelles informations devraient au moins enrichir les approches stratégiques et tactiques du SEO. Comprendre les signaux utilisés par Google permet d'adapter et d'améliorer les pratiques existantes.

Source :
- How SEO moves forward with the Google Content Warehouse API leak (Search Engine Land), 30/05/2024
Articles complémentaires :

Après le Google Leak, place aux hypothèses !

Danny Sullivan répond au Google Leak : les clics pas si importants pour Google ?

Google Leak : de nouvelles découvertes SEO !

Google Leak : Réponse de Google et doutes des SEO

Révolution ou menace ? Les AI Overviews de Google sous le feu des critiques






 Participez à notre 1ère étude sur le netlinking & les relations presse
Participez à notre 1ère étude sur le netlinking & les relations presse
 À gagner : 3 abonnements d’un an à Réacteur.com
À gagner : 3 abonnements d’un an à Réacteur.com
 Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Nous sommes devant une fuite exceptionnelle et certains font la fine bouche. Mike King obligé de se justifier… ^^
Autant ne plus rien écrire sur le SEO dans ce cas 😀
Je me rappelle des « pressions » sur RF quand il parlait de certains critères réfutés. Force est de constater qu’il avait raison.