

Découvrez les coulisses du géant de la recherche : Google a été tenu de dévoiler des documents internes éclairant le processus de classement des résultats de recherche, lors de son procès antitrust.
Révélation des méthodes de classement de Google
Les documents récemment publiés par le Département de la Justice des États-Unis offrent un aperçu des coulisses de Google, notamment sur la manière dont le géant de la recherche classe les résultats. Ces 7 documents internes, qui incluent des présentations PowerPoint et des mails, mettent en lumière les critères et les processus qui influencent la visibilité des pages web dans les résultats de recherche de Google.
Attention : certains de ces documents datent de plusieurs années, les informations contenues doivent donc être prises avec des pincettes, ayant pu être modifiées entre temps.
Interactions utilisateurs
Le premier document est une présentation PowerPoint rédigée en grande partie par Eric Lehman. Elle date de 2017. Toutes les pages ne sont pas accessibles.

D’après la diapositive “Les 3 piliers du classement”, Google met en avant 3 éléments :
- le corps : ce que le document dit de lui-même ;
- les ancres : ce que le web dit du document ;
- les interactions : ce que les utilisateurs disent du document.
Google précise que les clics peuvent être utilisés comme substitut aux interactions des utilisateurs. Dans leur globalité, les interactions incluent les clics, l’attention portée à un résultat, les clics sur un carrousel, le survol de la souris, le scroll et la saisie d’une nouvelle requête.
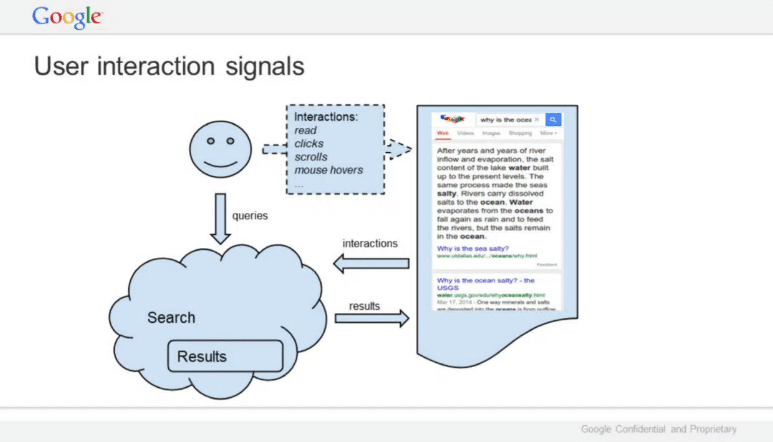
Classements
Le deuxième document révélé est une présentation préparée par Eric Lehman, en 2016, à propos des classements. Il date donc de 7 ans, ce qui signifie que Google a connu de multiples évolutions depuis. Il n’en est pas moins intéressant, mais ne le prenez pas pour acquis aujourd’hui.

Lehman déclare entre autres que Google fait semblant de comprendre les documents, mais ce n’est pas le cas : “Notre capacité à comprendre directement les documents est minime. Nous observons comment les internautes réagissent aux documents et mémorisons leurs réponses”.
“Au-delà de quelques éléments de base, nous regardons à peine les documents. Nous regardons les internautes. Si un document suscite une réaction positive, nous pensons qu’il est bon. Si la réaction est négative, il est probablement mauvais”.
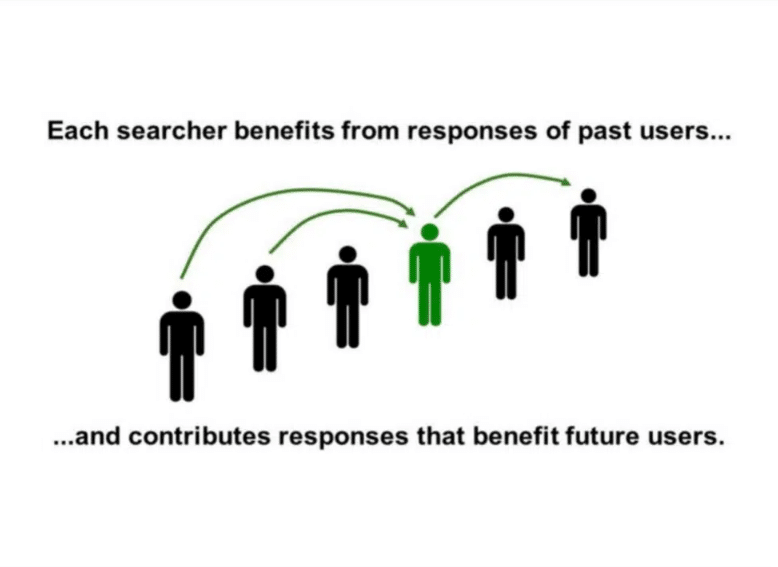
Cette diapositive montre que chaque chercheur bénéficie des réponses des précédents chercheurs, pour apporter de meilleures réponses. Le moteur de recherche apprend des précédentes interactions pour que l’expérience s’améliore en continu.
Si les interactions utilisateurs sont certainement toujours importantes pour classer les résultats, il va sans dire que la compréhension des contenus par Google s’est considérablement améliorée depuis 2016.
Qualité de la recherche
L’auteur de cette présentation n’est pas clair, mais elle date de novembre 2018. Encore une fois, certaines informations sont sûrement toujours correctes, mais d’autres critères ont dû être ajoutés depuis.

Google aborde 18 aspects de la qualité de la recherche : pertinence, qualité des pages, popularité, fraîcheur, localisation, langue, personnalisation, écosystème web, mobile-friendly, spam, autorité, confidentialité, etc.
Cette présentation indique aussi que les clics sont difficiles à interpréter, et donc pas un bon signal de classement : un rétropédalage par rapport à la présentation de 2017 ? Cela ne veut pas dire que les clics ne sont pas utilisés dans le système de classement aujourd’hui, mais peut-être que leur importance est à pondérer ?
Google est magique
Retour en 2017 avec la présentation “Google est magique”, qui contient plusieurs slides intéressantes.
Notamment comment la recherche Google ne fonctionne pas :
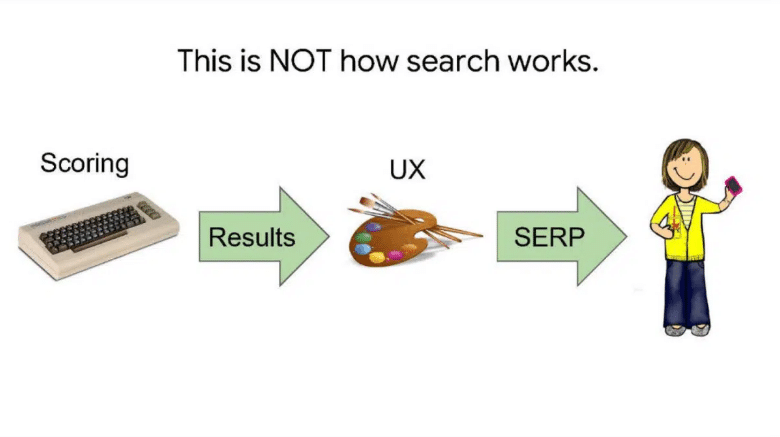
Et comment elle fonctionne :
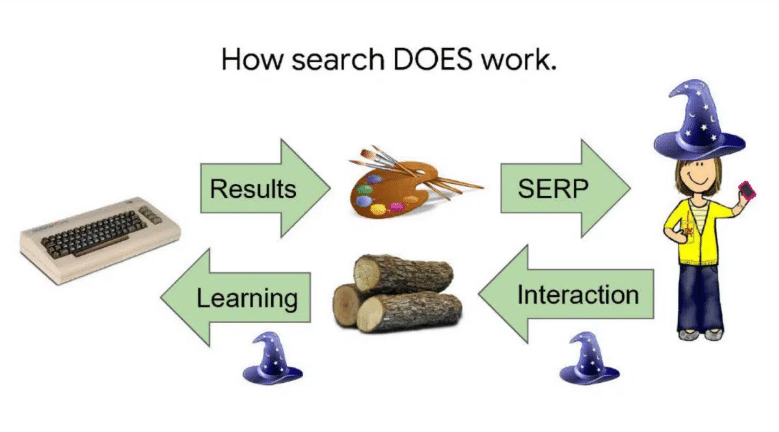
La première slide n’était donc pas fausse, mais incomplète car elle ne prenait pas en compte le deuxième flux d’informations, de l’utilisateur au moteur de recherche. Les actions sont enregistrées et cela permet de créer des modèles.
“La source de la magie de Google réside dans ce dialogue bidirectionnel avec les utilisateurs. À chaque requête, nous transmettons des connaissances et récupérons un peu en retour. Ensuite, nous donnons un peu plus et récupérons un peu plus en retour. Ces éléments s'additionnent. Après quelques centaines de milliards de retours, nous commençons à avoir l’air plutôt intelligent ! Ce n’est pas la seule façon d’apprendre, mais c’est la plus efficace”.
Les 10 liens bleus posent une question : quel résultat est le meilleur ? La réponse est un clic. La recherche d’images fonctionne de la même façon, en demandant à l’internaute quelle image est sa préférée.
Logs et classement
Cette présentation de 2020 (déjà plus récente !) aborde le rôle essentiel des logs dans le classement et la recherche.
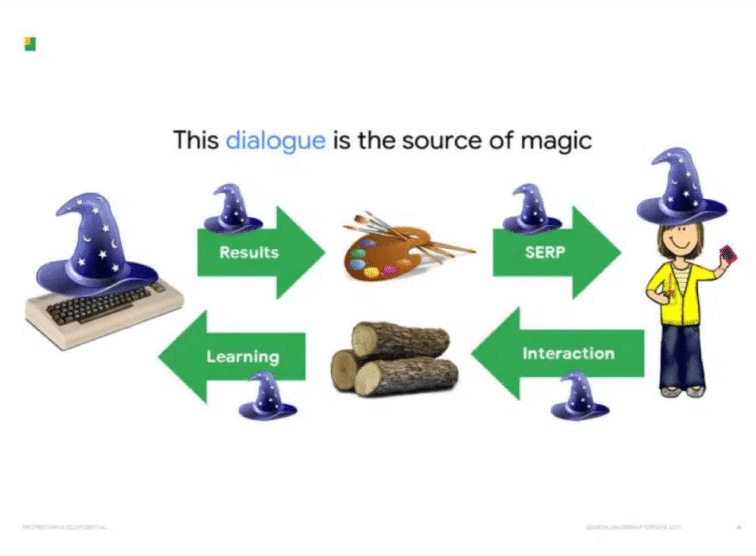
On peut être rassurés, car le fonctionnement de Google semble ne pas avoir changé depuis la présentation de 2017, la slide étant quasiment identique.
“La recherche est un peu comme un “potluck”, où chaque personne apporte un plat à partager. Il s’agit d’une très grande variété de plats que tout le monde peut apprécier. Mais cela ne fonctionne que parce que chacun contribue un peu.
De la même manière, la recherche s’appuie sur une énorme masse de connaissances. Mais ce n’est pas quelque chose que nous créons. Au contraire, tous ceux qui viennent effectuer une recherche apportent un peu de connaissances au système dont tout le monde peut bénéficier”.

Google parle ensuite de l’extraction de jugements de valeurs à partir des comportements des utilisateurs.
“Les logs ne contiennent pas de jugements de valeur explicites : c'était un bon résultat de recherche, ou celui-ci était mauvais. Nous devons donc réfléchir à la manière de traduire les comportements des utilisateurs enregistrés en jugements de valeur. La traduction est vraiment délicate, un problème sur lequel les gens travaillent assez régulièrement depuis plus de 15 ans. Les gens y travaillent parce que les jugements de valeur sont le fondement de la recherche Google. Si nous parvenons à extraire une fraction d'un peu plus de sens d'une session, nous obtiendrons environ un milliard de fois plus le lendemain. Le jeu de base est que vous commencez avec une petite quantité de données de « vérité terrain » qui indiquent que telle chose sur la page de recherche est bonne, ceci est mauvais, ceci est mieux que cela. Ensuite, vous examinez tous les comportements des utilisateurs associés et vous dites : “Ah, c'est ce qu'un utilisateur fait avec une bonne chose ! C'est ce qu'un utilisateur fait avec une mauvaise chose ! C’est ainsi qu’un utilisateur montre sa préférence !” Bien sûr, les gens sont différents. Nous n’obtenons donc que des corrélations statistiques, rien de vraiment fiable”.

L’auteur du document confirme ensuite que les logs sont fondamentaux pour les classements du moteur de recherche :
“Comme je l'ai mentionné, non pas un seul système, mais un grand nombre de classements sont construits sur des logs. Il ne s’agit pas seulement de systèmes traditionnels, comme celui que je vous ai montré plus tôt, mais également des systèmes d’apprentissage automatique plus avancés, dont beaucoup ont été annoncés en externe : RankBrain, RankEmbed et DeepRank. (...) D'une manière générale, je pense qu'une énorme partie des activités de Google est liée à l'utilisation des logs dans le classement”.
Classement mobile / desktop
Un e-mail à propos des différences entre le classement des recherches sur desktop et sur mobile a également été rendu public, mais il date de 2014. Autrement dit, le trafic mobile commençait à peine à dépasser le trafic desktop… Alors qu’aujourd’hui, tous les sites sont indexés sur leur version mobile !
Premières expériences avec BERT
Enfin, un tout petit document contenant une liste à puces en vue d’une présentation pour Sundar Pichai, datant de septembre 2019, a été ajouté à la liste de pièces.
2 points sur BERT sont néanmoins intéressants :
- “Les premières expériences avec BERT appliquées à plusieurs autres domaines de la recherche, y compris le classement Web, suggèrent des améliorations très significatives dans la compréhension des requêtes, des documents et des intentions.”
- "Bien que BERT soit révolutionnaire, ce n'est que le début d'un bond en avant dans les technologies de compréhension du langage naturel."
Tous ces documents, bien qu’utiles à connaître pour améliorer notre compréhension du fonctionnement de Google, sont à prendre avec précaution. Les parties confidentielles ont été supprimées. Ce qui est public doit donc être de moindre importance. Peut-être parce que ces informations étaient déjà plus ou moins connues ? Ou parce qu’elles ne sont plus d’actualité ? Certaines informations, comme les interactions utilisateurs ou les logs sont néanmoins intéressantes et doivent certainement être prises en considération dans votre stratégie SEO.
Articles complémentaires :

Les 10 secrets du référencement WordPress révélés par Daniel Roch !

Gemini de Google : Ce que vous devez savoir sur le partage de vos données et leur utilisation par l’IA

Mise à jour de la politique d’évaluation des produits de Google sur les avis générés par IA






 Participez à notre 1ère étude sur le netlinking & les relations presse
Participez à notre 1ère étude sur le netlinking & les relations presse
 À gagner : 3 abonnements d’un an à Réacteur.com
À gagner : 3 abonnements d’un an à Réacteur.com
 Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Super intéressant comme article. Après, ce qui était vrai hier est peut être faux aujourd’hui – ou du moins, plus nuancé – avec le nombre de leurs Maj qu’ils font au quotidien. Toujours intéressant de lire cela, en tout cas.
Bonjour Matthieu,
Effectivement, s’ils ont pu être partagés durant le procès c’est certainement que les pratiques ont au moins un peu évolué avec le temps, même si la base reste la même 🙂
Bonne journée !
Article très intéressant, merci 🙂
L’UX et le Customer Journey sont clairement des indicateurs du moment pour GG