


De nombreux éditeurs de sites web, notamment récents, en ont fait l'amère expérience : Google n'arrive plus à indexer, voire même juste à crawler bon nombre de pages à l'heure actuelle. Est-ce uniquement un bug temporaire ou un problème plus profond, né d'une volonté de lutte contre le spam et le contenu de faible qualité ? Voici quelques éléments de réponse...
On le sait, Google connait de très gros problèmes d'indexation des pages web depuis de nombreux mois :
- Plus spécifiquement sur des sites récents (mais pas que).
- Sur bon nombre de sites français (notamment en .fr), mais pas que.
Sur de nombreux sites donc, soit les pages sont crawlées mais non indexées, soit elles ne sont tout simplement pas crawlées. Dans la Search Console, les URL sont indiquées comme « Exclues », dans le rapport « Couverture », avec les messages « Détectée, actuellement non indexée » lorsqu'elles sont en attente de crawl ou « Explorée, actuellement non indexée » lorsqu'elles sont crawlées et en attente d'indexation. Ce phénomène est devenu suffisamment important pour se rendre compte que ce n'est pas un bug isolé pour un site web donné. C'est une vraie tendance forte du crawl et de l'indexation Google en ce moment.
La qualité des pages en premier critère
De nombreux webmasters m'ont posé des questions à ce sujet ces dernières semaines en m'indiquant l'adresse de leur site qui n'arrivait pas à être visité ou pris en compte par les robots du moteur. Il faut bien dire que, parmi ces sources d'informations, nombreuses étaient celles qui étaient de très faible qualité :
- Contenus trop courts.
- Articles émanant d'un site ayant une vision 100% SEO dans sa conception.
- Articles écrit uniquement pour créer un lien vers une page d'un autre site (depuis une plateforme de vente de liens ou autre).
- PBN.
- Etc.
Pour ce type de page, il est normal que Google ait mis en place un algorithme permettant de trier le bon grain de l'ivraie. Il faut l'assumer. Mais pour d'autres pages (et surtout d'autres sites), pourtant tout à fait valables et de bonne qualité, le problème est également et toujours présent.
Des outils tentent de corriger le tir, mais...
Bon nombre d'outils, la plupart utilisant l'API d'indexation de Google, se sont alors mis en place. Je vous engage à lire l'article de Daniel Roch publié cette semaine sur Réacteur, qui les a testés et où il nous dit ce qu'il en pense.
En les utilisant, et même si la situation n'est pas idéale, on arrive cependant à améliorer un peu la situation. Et le fait que ces outils d'indexation forcée fonctionnent (au moins un peu) montre bien l'incohérence totale de Google à ce niveau. En effet :
- Soit le moteur estime que les contenus en question sont de faible qualité et dans ce cas, il doit refuser leur indexation, quelle que soit la méthode utilisée pour les lui soumettre. Si une page est refusée à l'indexation via les méthodes naturelles (crawl du robot, Sitemap XML, etc.) mais acceptée via l'API, c'est juste du grand n'importe quoi !
- Soit il les indexe via l'API et à ce moment-là, cela signifie à la fois que la qualité des contenus n'est pas en cause, mais cela démontre aussi son incapacité actuelle à crawler le Web de façon naturelle et efficace.
Il s'agirait donc bien soit d'un bug du moteur et de ses robots, soit d'une faille dans son système de crawl, l'empêchant de crawler de façon propre et efficace les sites web, notamment récents. Un point gravissime, vous en conviendrez, pour un moteur qui se veut leader mondial du domaine !
(Notons ici cependant que certaines URL sont acceptées via les outils de soumission API, mais parfois désindexées par la suite par le moteur).
On peut faire actuellement le constat de la dégénérescence des capacités de crawl depuis plusieurs années : tout d'abord les multiples bugs qui ont jalonné les derniers mois au niveau de l'indexation et maintenant cette impossibilité à crawler et indexer des contenus récents. On peut même dire qu'à l'heure actuelle, Bing indexe bien mieux le Web que son concurrent historique. Qui aurait osé dire cela il y a quelques années ? Il est même beaucoup plus innovant à ce niveau, notamment avec le protocole IndexNow, proposé depuis quelques mois.
Mes conclusions
Qu'en est-il donc aujourd'hui ? Après avoir analysé de nombreux sites ayant du mal à se référencer et fait mes propres tests en internes, voici mes conclusions :
- Les problèmes actuels sont tellement répandus et incroyables qu'il est impossible que Google ne soit pas au courant de ces soucis. Il doit donc y avoir une explication logique.
- Google met peut-être en place à l'heure actuelle un système de filtre permettant de n'indexer que le contenu de bonne qualité. Mais c'est un euphémisme que de dire qu'il n'est pas encore au point, notamment avec le contenu récent, qui n'a pas encore proposé au moteur de signaux positifs concernant la qualité du contenu de la page et surtout du site qui les affiche.
- Si un des critères pour filtrer la qualité des contenus est bien sûr basé sur l'analyse des textes proposés en ligne, il semble indispensable d'obtenir rapidement des liens (backlinks) depuis un site « trusté » par Google (en qui le moteur a une certaine confiance : ancien, n'ayant jamais spammé, ayant une autorité et une légitimité forte dans son domaine, etc.). Chaque fois que nous avons fait un lien depuis un site trusté vers une page web ayant jusque-là du mal à s'indexer, la dite indexation s'est déclenchée comme par miracle dans la journée. Mais sans aucun impact sur l'indexation des autres pages du site-cible, en revanche. En d'autres termes, l'indexation d'une page ne déclenche pas celle des autres.
- Google tente certainement de créer des pare-feux pour contrer la potentielle invasion des contenus de spam rédigés de façon automatique par des algorithmes de type GTP-3. Si a priori aujourd'hui, le moteur sait distinguer les contenus automatisés des textes rédigés par des humains, qu'en sera-t-il dans quelques mois ou quelques années ? Il est donc tout à fait possible que Google mette en place des algorithmes allant dans ce sens, et s'occupant en premier lieu des pages web ayant un historique permettant d'analyser les signaux. L'incroyable situation actuelle de Google peut-elle signifier que les prochains contenus-cibles qui seront traités seront ceux qui ont été mis en ligne récemment, toujours en attente ? Ils seront alors analysés par l'algorithme qui sera alors à même de faire correctement son travail sur ce type de page ? On peut l'imaginer, sans en être certain, bien évidemment.
Il faut en tout cas espérer que la situation évolue rapidement, car celle-ci ne donne clairement pas une image positive de la firme de Mountain View et de sa capacité à maîtriser son moteur de recherche et la croissance actuelle du Web. Il faut bien avouer que ce n'était jamais le cas il y a quelques années de cela. Mais le Web était différent, et le niveau de spam à traiter le moteur très différent aussi (rappelons que Google découvre 40 milliards de pages de spam chaque jour !, et l'évolution actuelle des méthodes SEO n'y est pas pour rien).
Le moteur est-il dépassé par l'évolution exponentielle du Web et du nombre de pages et d'informations disponibles en ligne, et donc du spam dont il est bombardé ? Ou n'est-ce finalement qu'une péripétie temporaire et une situation qui sera rapidement corrigée par les équipes techniques de Google ? L'avenir proche nous en dira certainement plus à ce sujet… Une chose est sûre en tout cas : la situation actuelle doit absolument évoluer si Google tient à son hégémonie actuelle…
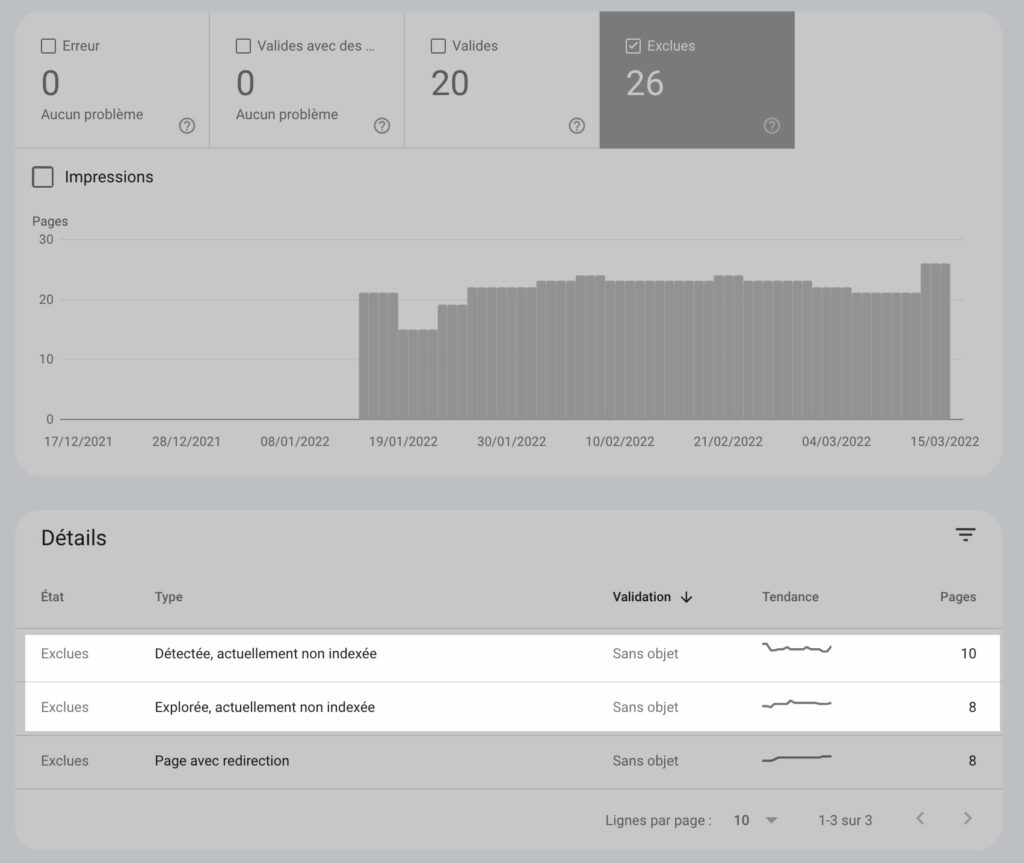
Exemple-type d'une (petit) site récent voyant de nombreuses pages - pourtant de bonne qualité et sans aucun signe de spam - non crawlées ou indexées.
Articles complémentaires :

Le bug d’indexation de Google Actualités est corrigé
L’indexation de Google Actualités est perturbée et impacte le trafic des éditeurs





 Participez à notre 1ère étude sur le netlinking & les relations presse
Participez à notre 1ère étude sur le netlinking & les relations presse
 À gagner : 3 abonnements d’un an à Réacteur.com
À gagner : 3 abonnements d’un an à Réacteur.com
 Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Hello,
On est en janvier 2023 et la plupart des pages mes sites (je suis éditeurs aussi) dont le contenu et la technique sont plutôt soignés, ne sont toujours pas indexées. Pire encore, GSC ne voit plus mes pages dans le sitemap. C’est incompréhensible et je vous avoue que cela commence à me chauffer car je perds un temps fou à faire du travail de qualité… pour plus grand chose. En espérant que Google se bouge…
Bonjour,
je souscris complètement à votre propos, aujourd’hui Google est complètement dépassé.
J’ai signalé plusieurs fois des sites référencés sur google shopping et qui ne sont que des arnaques.
Ce matin, je fais une recherche ‘avis memo 360’ suite à une publicité que j’ai vu passer.
Faites l’essai, TOUS les sites proposés par google ne sont que des rabatteurs qui vous proposent un lien ‘commandez ici’.
Désolant
Bonjour,
Je comprends un peu mieux la problématique globale en lisant votre article. Ce qui m’embête le plus, c’est que je suis un simple site personnel mettant en avant des photos. Malgré mes recherches je ne trouve rien sur comment améliorer le seo d’un site photo.
Seuls les réseaux sociaux peuvent me faire de la visibilité, mais il y a que Pinterest qui permet des liens directs à mes photos. Il est difficile pour moi d’avoir des backlinks.
Merci pour votre article qui reste très instructifs même plusieurs mois après sa publications.
Merci,
Marise
Bonjour,
Merci pour cet article et ces commentaires très instructifs.
J’ai le même souci sur le site e-commerce de ma cliente sorti en septembre 2021 sous la solution Square (assez connue aux US) et qui compte 221 Urls et seulement 15 indexées…
Savez-vous si le fait de faire une campagne Google Ads pourrait améliorer le référencement du dit site ?
Merci !
Peu de chances. Mais tout se tente ! Test and learn ! 🙂
Hello, j’utilise par moment des services tiers comme indexation.fr ou indexmenow mais je me demande comment ces sites peuvent faire une indexation aussi rapide, dans 50% des cas les urls que j’envoie sont indexées en moins d’une heure. Ca reste un service qui peut être cher si on utilise des requête avec des noms de villes en France. J’ai testé pas mal de chose mais rien d’aussi concluant que ces sites. L’API GOOGLE INDEX est bien si on a la propriété du site, mais quand c’est pour indexé des backlincks c’est embêtant. Quelqu’un a une idée sur le fonctionnement de ces outils?
Expliqué ici https://www.reacteur.com/2022/03/les-outils-daide-a-lindexation-de-pages-dans-google-sont-ils-efficaces.html 🙂
Ce type de problème se rencontre aussi avec des Noms de Domaine expirés de haute autorité. J’ai rédigé des artiocles de blog de parfois plus de 2000 mots (qualitatifs), avec requête pertinente aux yeux de l’internaute. Pourtant certains d’entre eux ne sont à ce jour pas indexés ! Je précise que pour les articles indexés, ces derniers apparaissent régulièrement sur la 1ère page de la SERP.
Un axe dont il faut parler aussi c’est la charge d’exploitation de google et sa consommation en energie… Si on veut maitriser son budget on doit aussi faire de concessions… J’avais une source disant que google na dans son index que moins de 1% du web… J’imagine meme pas la facture s’il passait à 2 %
Bjr. oui sujet traité sur Réacteur récemment : https://www.reacteur.com/2022/01/rechauffement-climatique-le-machine-learning-de-google-peut-il-se-mettre-au-service-du-climat.html
Quant à la taille du Web, je pense vraiment qu’il n’est pas dimensionnable à une Temps T. Donc 1 ou 2%, en soi, cela n’a pas vraiment de sens à mes yeux…
Bonjour Olivier, je suis pas d’accord avec le côté « invasion de contenu spam » avec gpt3.
Cet algo de création de contenu peut être utilisé pour faire des belles trames et je penses que 95% de SEO ou éditeurs de sites ne sont pas au courant du potentiel hors rédaction de GPT3 et l’apport très intéressant que cela peut avoir pour un site et qu’un rédacteur ne pourrait pas amener.
De plus, les problèmes d’indexation ne se limitent pas que au contenu. Combien de SEO vont voir les rapports des urls que sont détectées, crawlées mais non indexées ?
A mon avis très peu…..
Dans beaucoup de cas, on se retrouve avec des sites qui ont des erreurs de codages, des erreurs js, css, trop lent, micro data mal implémentées ou autre, même pour les sites soit disant au top….
Ce constat des problèmes d’indexation ne peut être imputé que au contenu (de part le constat de l’article)
Et sincèrement je préfère, à certain moment, avoir un contenu fait par l’IA (où je contrôle tout, trame, etc), plutôt que part un pseudo rédacteur SEO qui est fraichement sorti du moule grâce à la dernière formation rédaction SEO à la mode et qui va me faire payer (cher) un article qui ne se positionnera pas sur les moteurs de recherche.
Je rejoins Cyril sur quelques points.
Il ne faut pas tout mettre sur le dos de la « sacro-sainte » qualité du contenu que Google dit vouloir absolument. Un site lent avec du code médiocre,mauvais (voire obsolète) voit ses chances de crawl et d’indexation s’amoindrir. Par extension, le côté technique (dette) joue un rôle importante pour résoudre les soucis d’indexation à la longue.
J’en ai ma claque de voir des webmasters avec des images de plus de 1MO sur leur site en pagaille sur une même page. (avec des frameworks, des plugins, des bibliothèques… de programmation qui datent de mathusalem) et une mauvaise intégration de media. Il n’y a pas besoin d’être un développeur chevronné pour le voir. Et après, le webmaster en herbe ne comprend pas pourquoi, cela ne s’indexe pas. 🙂
Il y a un test à faire : demander une indexation manuelle d’une page qui s’indexe pas. Si au bout de 24 heures, elle est indexée et qu’elle le reste longtemps alors le site ne souffre peut-être pas des soit-disant « bugs » d’indexation de Google. (A mon avis) Le problème est ailleurs. Le contenu n’est pas forcement à remettre en cause. Par contre, si une URL s’indexe puis se désindexe rapidement. Alors, oui, là, il faut revoir le contenu. (Pas seulement de la page mais aussi du site dans sa globalité).
Ca, c’est un fait. De plus, tout n’est pas à jeter du côté de GPT3. Cependant, il faut un minimum de bon sens avant de vouloir s’intéresser à cette technologie. Elle n’est pas à mettre dans toutes les mains.
bonjour Olivier
Article très pertinent sur un sujet très problématique pour la plupart d’entre nous.
Heureusement qu’il existe des outils comme celui de Stephane Madaleno.
Par contre, je me demande si vous n’avez pas fait une inversion dans votre phrase « les URL sont indiquées comme « Exclues », dans le rapport « Couverture », avec les messages « Détectée, actuellement non indexée » lorsqu’elles sont crawlées et en attente d’indexation ou « Explorée, actuellement non indexée » lorsqu’elles ne sont pas crawlées »
Pour moi, ce que j’avais compris , c’est que « Détectée, actuellement non indexée , c’était la première étape de l’indexation: l’URL a bien été vue par Google, mais pas encore crawlée et de facto non indexée.
Et que la deuxième étape de l’indexation « Explorée, actuellement non indexée », c’était que l’URL avait été vue, détectée ET crawlée par Google mais pas encore indexée.
Merci d’avance de votre réponse pour m’enlever ce doute
Cordialement
Bernard
Oui, oui, c’est bien ça, pardon. j’avais inversé dans la rédaction. C’est corrigé, merci 🙂
De rien Olivier.
J’avais eu, à l’époque, un bon professeur en référencement 🙂
Comme quoi Formaseo est une très bonne formation.
Excellent article Olivier ! Merci !
On savait que le SEO n’est pas une science exacte mais avec cette problématique d’indexation chez Google, c’est carrément le grand flou artistique en ce moment. Pas facile d’expliquer ça aux clients en effet 😉
Difficile en effet de trouver une explication logique à ce qui se passe actuellement tant les cas diffèrent d’un site à l’autre et même sur un même site.
Ça sent quand même le « gros remaniement » du côté de l’algo de Google… Enfin, c’est mon sentiment.
Attendons de voir si les choses se stabilisent un peu dans les prochains mois / semaines.
Le triptyque [contenu de qualité + popularité + SEO Technique] va-t-il muter vers quelque chose d’encore plus quali ?
Ce qui est sûr, tu as raison, c’est que Google sait sûrement ce qu’il se passe.
Franchement sur des sites récents, L’indexation est devenu un vrai souci même avec du contenu long et de qualité…
Pour bing, c’est cool que l’indexation se passe bien mais pour ma part le trafic est toujours proche de 0 .
Payer pour faire indexer ses urls pourquoi pas mais quand on voit la M… qui passe sur Google actu en indexation ultra rapide y’a de quoi etre jaloux :/
Merci pour cet article qui synthétise bien ma hantise de ces derniers mois.
Comme beaucoup ici, j’ai fait des tests et j’ai encore du mal à voir ce qui arrive à être indexé de ce qui ne l’est pas.
Première chose : la demande d’indexation manuelle dans Google Search Console n’aide pas beaucoup.
Ensuite, le contenu original, de qualité ou non, ne semble pas être un critère.
Sur un site, j’ai ajouté 15 pages en décembre : elles ne sont toujours pas indexées.
Sur un autre site que l’on m’a confié, j’ai du ajouter du contenu sur la seule et unique page du site et créer une fiche d’établissement Google. Une fois la fiche d’établissement validée, le site a été indexé (et honnêtement son contenu est très léger).
Sur un site tout beau tout neuf au contenu assez pauvre (en quantité) mais pertinent (de qualité) : il a été indexé en 3 jours. Ici l’astuce c’est que le site a été créé avec Wix et que le site a été connecté à Google Search Console via api (depuis le tableau de bord Wix).
Bref, un site Wix qui s’indexe mieux qu’un site propre sous WordPress, c’est un peu le monde à l’envers cette année 2022 en termes de SEO.
Je pense qu’Olivier a mis le doigts sur un truc important :
Google n’arrive plus à crawler. Du coup, faute d’arriver à « contrôler » les robots d’indexation Google depuis la Search Console, il faut passer par autre chose : fiche d’établissement, backlinks ou autres ruses (redirections 301 ?).
Des articles que je rédige moi-même sur un site A ne sont pas indexés, même au bout de 2 mois.
D’autres articles sur un site B sont indexés dans la journée.
Je suis la même personne, avec le même style de rédaction.
Ma théorie : mon site A est peut-être pénalisé en ce qui concerne les nouveaux contenus. En revanche, si je met à jour un ancien contenu, pas de souci pour prendre en compte la maj de la part de Google.
J’ajoute que je soumets systématiquement mes nouvelles pages ou mes majs du site A à Google via la GSC.
Bonjour Olivier, cela décrédibilise aussi fortement les agences web : comment expliquer à un client que son site vitrine est introuvable sur Google ? Parfaitement indexé par Bing par contre…
Nous créons des sites Internet depuis 2005, le métier se complique…
Je pense que Google est un peu dépassé par la taille du web et qu’il ne peut pas tout crawler. Il fait un tri entre site nouveaux qui mettent à jour et ceux qui ajoutent du contenu et les nouveaux sites qui peuvent attendre un peu l’indexation avant d’être plus pertinents sur certaines requêtes. Google est là pour vendre de la pub. Donc en toute logique, un nouveau site (nouvelle entreprise ?), aura besoin de faire de la pub pour se faire connaître rapidement. Gagnant gagnant.
Je confirme absolument. Du contenu de qualité sur un site d’autorité et présent dans la sitemap, non indexé pendant des mois, puis indexé en moins de 24h en demandant une reindexation via la search console.
Je garde un œil avec mon outil IndexCheckr et ces pages demeurent bien indexées. Il s’agit bien de problèmes techniques à mon sens et cela fait des mois que cela dure.
À noter que Google est responsable en premier lieu de cette course au contenu.
Pour le coup, ta dernière phrase manque d’arguments 🙂
Bonjour et merci pour cet article. Je rencontre des problèmes d’indexation de produits sur un site e-commerce mais sur un site d’offres d’emploi très récent, aucun soucis.
Ça fait plus d’un an que le problème est apparu sur Google et il concerne en effet surtout les nouveaux contenus. .
Le moteur semble être flemmard et si il vient bien re-scanner les pages existantes, il ne suit pas les nouveaux liens tout seul..;
On a beau insister sur la console, il faut parfois plusieurs mois pour référencer un article.
Pour bing, il obéit plutôt bien aux demandes de référencement mais pour ce qui concerne la pertinence des résultats….
Pour les images,
il est capable d’afficher parfois dans les résultats les 20 ou 30 premières images provenant d’un même site, ce qui n’est pas un signe de pertinence ni d’un bon algorithme
Même problème sur un petit site, dont les nouvelles pages ne sont pluss indexées depuis novembre 2021 au moins… En termes de qualité, il y a un peu de tout, dont un long article de + de 2500 mots sur une requête pertinente. J’ai fait du maillage depuis des pages indexées, le contenu est diffusé via plusieurs sitemaps, et malgré tout, rien !
Je confirme pour le timing de novembre 2021 et le début des soucis.
Personnellement j’ai ce problème sur des articles de plus de 2000 mots rédigés avec amour et basés sur une bonne connaissance du sujet qu’ils traitent. Je suis rassuré de voir que je ne suis pas le seul. Merci pour cet article Olivier !