


Google a récemment publié un article pour indiquer les deux raisons qui font qu'il supprime des pages de son index. Si elles semblent légitimes, deux autres sont certainement à nos yeux tout aussi évidentes...
Danny Sullivan a publié un post cette semaine sur l'un des blogs officiels de Google pour expliquer les deux raisons qui peuvent pousser Google à "blacklister" (supprimer de l'index, donc désindexer) certaines pages web. Nous allons les décrire ci-dessous, en en ajoutant deux autres, plus proches du monde du SEO...
Blacklister pour suivre la loi
« Nous avons (…) la ferme obligation et la responsabilité de respecter la loi et de protéger nos utilisateurs. Lorsqu'un contenu est contraire à la législation locale, nous le supprimons de l'accès à Google Search. » Cette première raison est logique : si un contenu disponible sur le Web est contraire à la loi (et Dieu sait s'il en existe !), il est logique qu'il ne se retrouve pas dans les résultats de recherche. Mais Google note également, avec raison : « pour de nombreuses questions, telles que la confidentialité ou la diffamation, nos obligations légales peuvent varier d'un pays à l'autre, car les différentes juridictions sont parvenues à des conclusions différentes sur la manière de traiter ces sujets complexes. » Et ce n'est pas la moindre des complexités que de gérer ces aspects géographiques, chaque pays dépendant de sa loi et inversement. Le post donne quelques exemples :« dans le cas d'un contenu protégé par des droits d'auteur, nous ne pouvons pas automatiquement confirmer si une page donnée hébergeant ce contenu particulier dispose d'une licence pour le faire, nous avons donc besoin que les titulaires de droits nous le disent. En revanche, la simple présence de matériel pédopornographique sur une page est illégale dans la plupart des juridictions. Nous développons donc des moyens d'identifier automatiquement ce contenu et de l'empêcher d'apparaître dans nos résultats. »
Blacklister pour sauvegarder la qualité des contenus
Google va également essayer de traquer certaines données personnelles comme des informations financières ou médicales, de pièces d'identité délivrées par le gouvernement et des images intimes publiées sans consentement afin qu'elles ne soient disponibles via le moteur, tout comme pour des pages pouvant nuire à la réputation en ligne d'une personne. Et ces actions peuvent également aider dans sa lutte contre le spam : « par exemple, lorsque nous recevons un volume élevé de demandes de suppression de droits d'auteur valides pour un site donné, nous pouvons l'utiliser comme un signal de qualité et rétrograder le site dans nos résultats. Nous avons développé des approches similaires pour les sites dont nous avons retiré les pages dans le cadre de nos politiques volontaires. Cela nous permet non seulement d'aider les personnes qui demandent les suppressions, mais aussi de lutter de façon évolutive contre ce problème dans d'autres cas. »
Ces deux raisons de supprimer du contenu du moteur sont logiques et classiques. Mais on peut (au moins) en rajouter deux autres, plus proche de notre travail au quotidien en termes de SEO :
Blacklister pour lutter contre le spamdexing
Rappelons que Google découvre plus de 25 milliards de pages de spam chaque jour. Il est bien évident que le moteur ne va pas garder au chaud toute cette fange de contenus sans intérêt et qu'il va sans atermoiement jeter tout ça à la poubelle, puisque cette lie n'a aucun intérêt, ni pour lui, ni pour les internautes. Bref, tout ce qui résulte de la "triche SEO" (black hat) risque bien, à un moment ou à un autre, de connaître le même sort.
Blacklister pour des raisons techniques
Il n'est qu'à aller faire un tour dans la Search Console, rapport « Couverture », puis dans l'onglet « Exclues », pour s'apercevoir que Google refuse la plupart du temps plus de pages qu'il n'en accepte pour un site web donné. Les raisons sont multiples : pages en "noindex", contenu dupliqué, pages avec très peu de texte (souvent des Soft 404), etc. Chaque jour, ce sont là aussi des milliards d'URL que Googlebot va rapatrier et qui seront mises… à l'index mais pas dans l'index 😉
On le voit, les raisons qu'a Google de supprimer du contenu de son index sont multiples. On pourrait d'ailleurs assez facilement en trouver d'autres. Le Web grossit à vue d'œil, de façon exponentielle, et le moteur doit trouver au quotidien un équilibre entre le fait de garder le meilleur de la Toile tout en supprimant ce qui a moins d'intérêt. Et c'est un travail énorme et quotidien… Les récents problèmes et bugs d'indexation de Google, depuis deux ans, montrent d'ailleurs bien que c'est une situation fragile et que la remise en cause permanente est de mise à ce sujet…
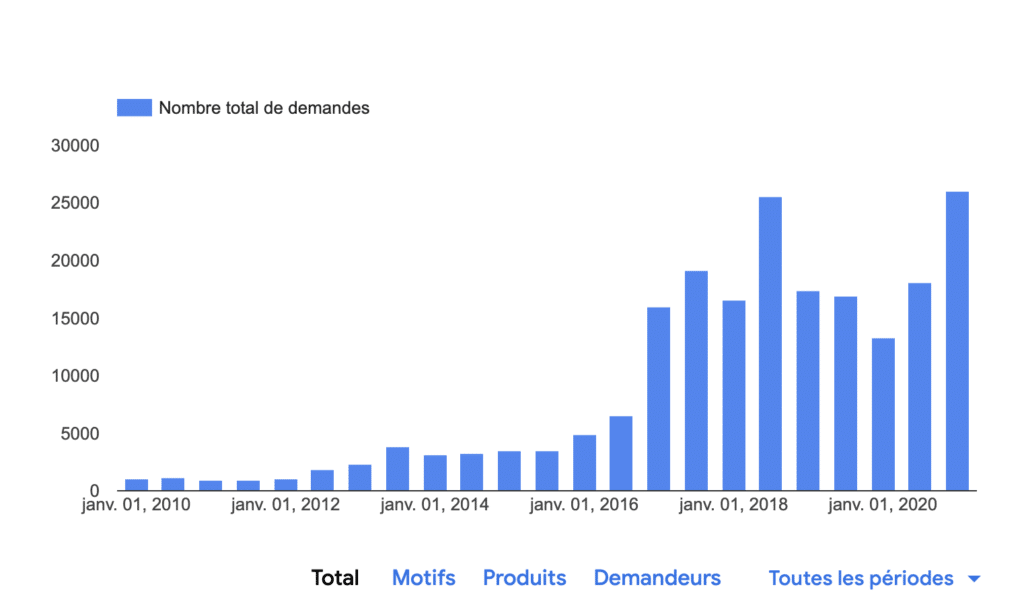
Un exemple avec le nombre de demandes gouvernementales de suppression de contenu à Google. Source de l'image : Google
Articles complémentaires :

Pourquoi Google positionne-t-il mieux les contenus IA ?

Google News face au défi du contenu IA

Produire du contenu Google-friendly avec l’IA générative
 l’algorithme Google")




 Participez à notre 1ère étude sur le netlinking & les relations presse
Participez à notre 1ère étude sur le netlinking & les relations presse
 À gagner : 3 abonnements d’un an à Réacteur.com
À gagner : 3 abonnements d’un an à Réacteur.com
 Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Quelques minutes suffisent. Un grand merci par avance à tous les participants !