

Wikipedia va lancer dans les mois qui viennent une nouvelle offre, baptisée « Wikimedia Enterprise », qui a pour vocation de fournir aux grands sites web mondiaux (Google, Facebook, Amazon, etc.) un accès privilégié aux données de son encyclopédie en ligne, assorti de services spécifiques...
Si on en croit le site Wired, la Wikimedia Foundation, organisme à but non lucratif qui gère l'encyclopédie en ligne Wikipedia, envisage de lancer prochainement l'offre "Wikimedia Enterprise" (précédent nom de code : Okapi), un service payant, spécifique à la livraison de données pour les géants de l'Internet que sont Google, Yahoo!, Microsoft, Facebook, Amazon et autres, grands consommateurs des data extraites de son site, que ce soit pour les Knowledge Graph, les Featured Snippets, les assistants vocaux et bien d'autres fonctionnalités de leurs outils respectifs.
Au programme : un accès privilégié aux données, plus rapide et vérifiées pour une fiabilité accrue, ainsi éventuellement que d'autres services spécifiques. Mais cela n'empêchera pas un accès "classique" et gratuit pour les autres acteurs, même à objectif commercial, comme actuellement. La gratuité de la disponibilité des informations fournies par Wikimedia n'est pas remise en cause. Le nouvel outil est plus une offre "VIP" avec des services supplémentaires.
Reste à voir comment cela se passera avec des partenaires privilégiés comme Google, qui est déjà donateur de Wikipedia pour des sommes importantes, mais qui génère également une baisse de trafic sur Wikipedia depuis longtemps, de par l'utilisation de ses données dans ses SERP (mais le modèle économique de Wikipedia n'est pas non plus basé sur le trafic). Et la très forte utilisation par Google des données de l'encyclopédie coûte cher à la fondation, à une époque où Google arrive de mieux en mieux à générer en interne des résumés pour son Knowledge Graph au travers d'algorithmes d'intelligence artificielle (voir illustration ci-dessous). Bref, cette relation parfois ambigüe pourrait peut-être être régularisée par l'offre Wikimedia Enterprise.
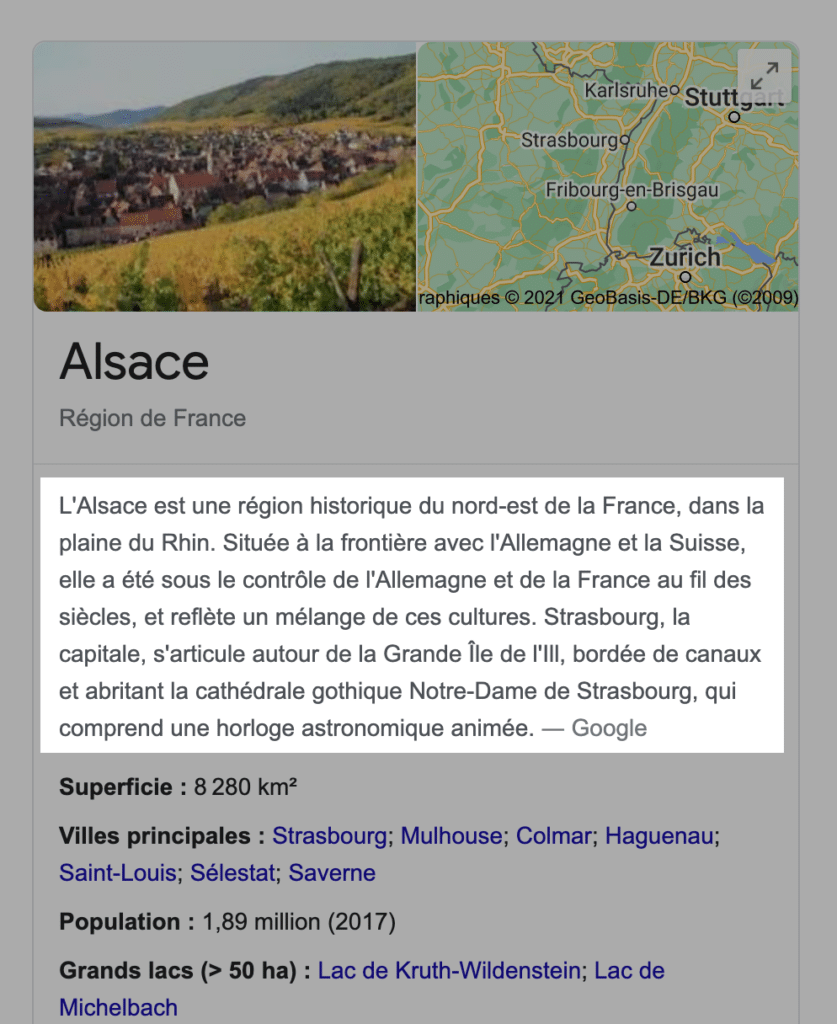
Exemple de résumé auto-généré par Google, sans utilisation de Wikipedia, dans un Knowledge Graph. Source de l'image : Abondance
Pour l'instant, la page d'accueil du site propose un message d'attente (Wikimedia Enterprise est un nouveau produit de la Wikimedia Foundation, l'organisation à but non lucratif qui gère Wikipédia et d'autres projets Wikimedia. Wikimedia Enterprise fournit des outils et des services de développement payants qui permettent aux entreprises et aux organisations de consommer et de réutiliser plus facilement les données de Wikimedia.) sans date de lancement précise ( Nous lancerons le produit dans le courant de l'année 2021).

Page d'accueil du site Wikimedia Enterprise. Source de l'image : Abondance
Articles complémentaires :

Faut-il bloquer les robots de ChatGPT pour sauver ses données ?

Gemini Business & Enterprise : l’IA accessible aux entreprises

Google modifie les données structurées pour les annonces spéciales

Nouvelles données structurées pour les forums et les profils !





 Participez à notre 1ère étude sur le netlinking & les relations presse
Participez à notre 1ère étude sur le netlinking & les relations presse
 À gagner : 3 abonnements d’un an à Réacteur.com
À gagner : 3 abonnements d’un an à Réacteur.com
 Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Une réflexion : Wikimedia incite les utilisateurs à illustrer les articles avec des photos (qui du coup deviennent libre de droit, autant que je le sache).
Si la fondation se met à ‘vendre’ ses données, il y a en partie un détournement de l’esprit initial : fournir textes et images, libre de droit en accès libre.
Mais, bien sûr c’est plutôt un commentaire pour la fondation elle-même
Norbert Pousseur, photographe
Wikimedia explique que l’offre « Entreprise » ne touchera ne rien l’esprit initial de l’encyclopédie. Les données resteront gratuites pour les autres, seuls les très gros consommateurs de ces data sont concernés par cette nouvelle offre.
Oui, mais cela pose tout de même question…
Cette re-réponse, juste pour vous remercier pour vos articles..
N Pousseur
Question hors sujet:
La problématique est bien connue. Mais, en ce qui concerne l’exemple cité (Alsace), on remarque que le texte figure sur d’autres sites.
Alors,
soit l’un deux est l’auteur initial du texte et Google trompe l’internaute en indiquant une source erronée (la sienne)
soit (et c’est très possible) le texte provient tel quel d’un site qui n’est pas accessible en français (site qui n’existe plus, encyclopédie payante, site en autre langue traduit par Google,…) et Google trompe aussi l’internaute quant à la source,
soit encore (comme vous le pensez) ce texte a été auto-généré par Google et les sites qui le reproduisent sont de purs spams et Google ne s’en rend même pas compte puisqu’il indexe ces contenus (sic !).
Curieux de trouver parmi ces spammeurs d’un texte français, un site culturel suédois en anglais ! (et apparemment sérieux !) Curieux aussi que dans tous ces sites spammeurs, le moteur de recherche interne ne trouve pas le contenu alors que Google le reprend bien dans ses SERPs.
Que pensez-vous de tout cela ?