
Google a lancé une petite bombe ce matin avec la prochaine arrivée (pour les requêtes anglophones dans un premier temps) de BERT, la plus grosse évolution de l'algorithme depuis 5 ans. Attention, gros changements à prévoir dans les SERP sous peu...
Attention, grosse mise à jour de l'algorithme en vue chez Google, selon l'annconce effectuée ce matin sur le blog officiel du moteur.
Dénommé BERT (acronyme de Bidirectional Encoder Representations from Transformers, une technique basée sur les réseaux neuronaux pour le traitement du langage naturel (NLP)), cette mise à jour va, selon les dires du moteur, être une avancée importante dans l'évolution de la recherche sur le Web : "Grâce aux dernières avancées de notre équipe de recherche dans la science de la compréhension du langage - rendue possible grâce à l'apprentissage automatique - nous améliorons considérablement la façon dont nous comprenons les requêtes, ce qui représente le plus grand bond en avant des cinq dernières années et l'un des plus grands bonds en avant dans l'histoire du Search. " Rien que ça…
BERT est conçue pour mieux comprendre le contexte de l'intention de recherche
L'idée de BERT est d'utiliser des modèles qui traitent les mots les uns par rapport aux autres dans une phrase, plutôt qu'un par un dans l'ordre de la lecture. Les modèles BERT peuvent donc considérer le contexte complet d'un mot en examinant les mots qui le précèdent et le suivent, ce qui est particulièrement utile pour comprendre l'intention derrière les requêtes de recherche. Le contexte de l'intention de recherche sera alors plus facilement analysé et la réponse plus précise et pertinente.
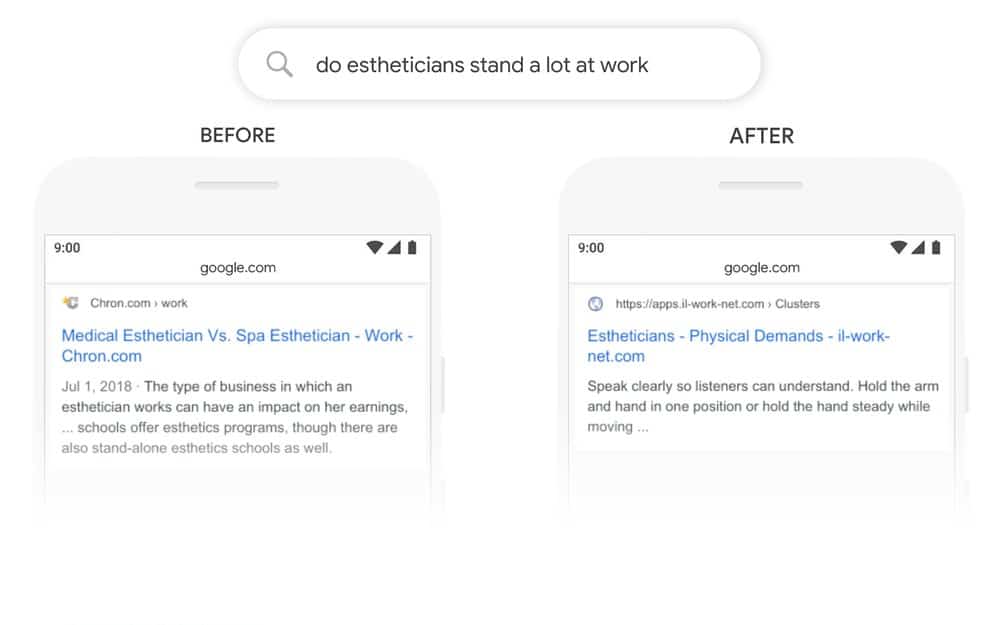
Un des exemples fourni est la requête "do estheticians stand a lot at work?" : auparavant, l'algorithme utilisait une approche consistant à faire correspondre les mots-clés, c'est-à-dire à faire correspondre le terme "stand-alone" dans le résultat avec le mot "stand" dans la requête. Mais ce n'était pas l'utilisation correcte du mot "stand" dans le contexte. Le modèle BERT comprend désormais que le mot "stand" est lié au concept des exigences physiques d'un travail, et affiche une réponse plus utile.
Ce nouveau système devrait toucher environ 10% des recherches en anglais dans un premier temps, et il sera adaptés à d'autres langues à court et moyen termes. BERT est déjà appliqué dans de nombreux pays pour les featured snippets, avec des améliorations significatives dans des langues comme le coréen, le hindi et le portugais.
Bref, les SERP devraient prochainement jouer au yo-yo pour la langue anglaise prochainement, et en français à court terme. Autant être vigilant et analyser cette évolution dès qu'elle arrivera sur nos côtes. Ça risque de swinguer fort !
Articles complémentaires :

Le lancement de Google Bard reporté en Europe

Lancement de Gemini 1.5, l’intelligence artificielle capable de résumer la mission Apollo 11

De l’IA générative derrière certaines fonctionnalités Google depuis plusieurs années ?





 Participez à notre 1ère étude sur le netlinking & les relations presse
Participez à notre 1ère étude sur le netlinking & les relations presse
 À gagner : 3 abonnements d’un an à Réacteur.com
À gagner : 3 abonnements d’un an à Réacteur.com
 Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Quelques minutes suffisent. Un grand merci par avance à tous les participants !
La question que je me pose, c’est est-ce que les sites ciblés ne vont pas changer comme sur la medic update.
Seul le temps pourra nous le confirmer…
Merci pour cette information. Mais dites-moi, cela veut dire que le système de référencement va changer ? Est-ce que d’autres formes de sanction vont désormais apparaître ou comment cela va-t-il se passer ? En tout cas, merci pour cette information très utile.
Tout est là : https://www.reacteur.com/2019/11/bert-quelles-sont-les-technologies-derriere-lupdate-et-lalgorithme.html
Si j’ai bien compris, les contenus qui ont été rédigés pour les internautes et en prenant en compte leurs intentions de recherche seront plus visibles que les contenus orientés robots ?
Oui, en tout cas il faut l’espérer 😁
Voir mon article de ce matin a ce sujet
https://www.abondance.com/20191028-41166-plus-dinfos-sur-bert-le-nouvel-algorithme-de-google.html
BERT Vient renforcer la politique de Google pour prioriser la sémantique ansi satisfaire les internautes en leurs donnant un contenu plus pertinent
Il s’agit d’une très bonne nouvelle. Des pages qui ne sortaient dans les résultats par ce que le moteur n’arrivait pas à faire correspondre son index avec la requête, vont maintenant apparaître dans la SERP.
Il se trouve que nos chercheurs travaillent beaucoup sur ces approches. Les algorithmes actuels sont basés sur des approches que l’on appelle dans la recherche académique « bag-of-words model » BERT utilise des approches que l’on appelle « word association » ou encore « word collocation » qui est en effet beaucoup plus puissante.
Ces approches de « word association » sont utilisées pour toutes les problèmes NLP : keywords extraction, Automatic Text Generation, similarity computations, etc.
D’un point de vue scientifique, il s’agit en effet d’une énorme avancée pour le moteur de recherche car ces approches sont complexes et révolutionne la façon même d’appréhender les requêtes.
Mais d’un point de vue référenceur, agence SEO, annonceurs, etc. aucune inquiétude, encore une fois c’est une super nouvelle le fait que la relation sémantique entre les mots soit mieux maîtrisée va permettre de meilleurs résultats.
Ce qui est étonnant dans cette sortie, c’est plutôt pourquoi Google ne l’a pas fait avant… probablement pour des raisons de manque de précisions dans les résultats (sens des expressions clés). Je pense que les travaux récents en matière de génération automatique de texte menés par Google et pour lesquels la maîtrise de « word collocation » est primordiale pour obtenir de bons résultats, est à l’origine de cette découverte.
-Fabrice
Toutes les grosses mises a jour de Google font trembler la terre. Les annuaires tremblent aussi a chaque fois.
On se demande a quelle sauce on va se faire manger un peu plus de trafic , ou voir le RPM Adsense divisé par deux d’un coup …
La vie est dure … avec Google !
Les tests avaient commencé il y a déjà quelque temps, y compris en français sous certaines conditions.
J’ai même fait une démo en vidéo qui montre comment savoir quand GG comprend un sujet et quand il ne comprend pas complètement voire pas du tout.
On arrive aussi à savoir sous quel angle il comprend le sujet…
Je démontre le mécanisme en fabriquant un sujet en ajoutant des mots en principe « anodins » à l’expression-clé « New York » jusqu’à arriver à une phrase entière dont on peut être sûr que GG l’a compris.
Googler « Trouver les metamots qui claquent »…
C’est pas grave, plus Google saura comprendre et interpréter du contenu et plus le vrai travail quali rédactionnel et informationnel fonctionnera,
Ce qui veut dire que du contenu très quali d’il y a 2 ans qui fonctionne déjà pas mal aujourd’hui, après des mises à jours comme ça devrait en toute logique grimper dans les Serps laissant reculer du contenu un peu plus spamy qui aurait été devant (c’est rageant de constater ça au quotidien d’ailleurs)
C’est une façon de se dire que le temps passé à un SEO quali / informatif va de mieux en mieux se rentabiliser avec le temps.
Bon après espérions que l’algo soit au point et comprenne pas de travers, c’est en réalité ça le vrai danger.
Croisons les doigts et de toute façon, s’adapter c’est survivre 🙂
Tous les ans on nous sort des articles le SEO est mort ! et tous les ans il faut être de plus en plus calé en SEO pour être visible donc c’est pas près de s’arrêter le SEO.
Google sort sa Grosse BERTa 😉 !
A mon avis on va attendre un moment avant de le voir arriver sur les pays Francophones
Il aurait pu attendre Halloween pour déployer se nouveau monstre