

Il semblerait que, depuis peu, Google ajoute parfois à ses résultats de recherche des données financières ou administratives sur les entreprises, informations issues de sites comme societe.com ou verif.com. Accord commercial ou scraping ?...
On connaissait (depuis 2014) le fait que Google ajoute, dans ses résultats de recherche, un certain nombre d'informations lorsque le lien était issu de Wikipedia, comme dans les exemples ci-dessous avec, pour une entreprise, des données comme le nom du propriétaire, la société mère, l'activité, le directeur de publication, etc. :
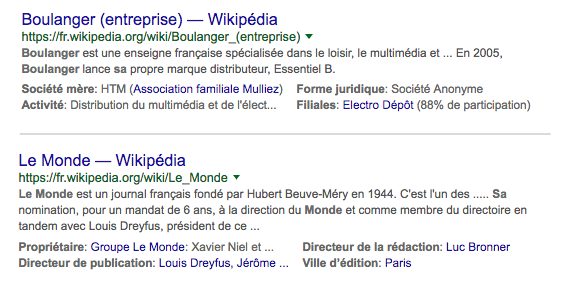 Affichage dans la SERP de données sur une entreprise, issues de Wikipedia... Source de l'image : Abondance |
Il semblerait que depuis quelques temps (à moins que cela ne soit plus ancien, mais nous ne l'avions jamais remarqué - et merci à Philippe de nous l'avoir signalé), ce sont des sites comme societe.com ou verif.com qui ont droit au même traitement, avec l'affichage d'informations comme le chiffre d'affaires, le code SIREN ou SIRET, le code APE, le capital social, etc. (voir illustration ci-dessous). Est-ce que cet affichage est dû à un partenariat avec ces sites ou Google scrape-t-il ces infos sans l'autorisation de la source ? Nul ne le sait. Toujours est-il que les pages en question n'ont pas de balises de données structurées spécifiques aux datas fournies. Donc si scraping il y a, il semble similaire à ce que propose Google avec ses featured snippets. SI vous avez plus d'informations à ce sujet, on est preneur !...
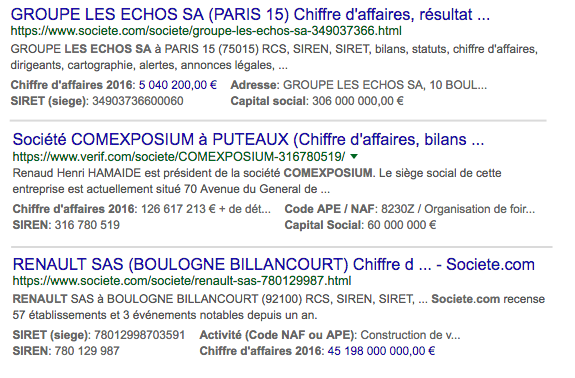 Affichage dans la SERP de données sur une entreprise, issues d'autres sites... Source de l'image : Abondance |
Articles complémentaires :

Google améliore les informations d’expédition et de retour dans les résultats de recherche

Google dévoile comment s’organise la guerre contre les fausses informations sur Maps

La fonctionnalité Perspectives de Google débarque dans les résultats sur mobile

Google ajoute la Wayback Machine dans ses résultats : explorez l’histoire du web !





Quitte à ce que Google affiche nos données directement dans les résultats de recherche, autant que ce soit fait proprement.
Aussi, j’ai lancé un projet pour normaliser un marquage Schema.org dédié aux informations légales et financières sur les entreprises.
Sur les conseils de Thad Guidry, Data Architect chez Ericsson, l’idée est de se baser sur le standard international de la comptabilité, l’IFRS, afin que cela fonctionne au niveau international.
Richard Wallis « Schema.org & Structured Web Data Consultant – Developer Advocate at Google via Adecco UK », qui a participé au récent typage Schema.org des produits financiers a également proposé son aide.
https://github.com/schemaorg/schemaorg/issues/1783
Merci Olivier pour ces précisions sur les extraits structurés
Ce sont les Extraits Structurés, annoncés par Google sur son blog Research en 2014. Ca dépend du type de requête, c’est vraiment pour des éléments pour lesquels on peut apporter beaucoup d’informations factuelles complémentaires (composition pour les médicaments, caractéristiques techniques d’un produit).
La seule optimisation possible est de présenter ses informations sous forme de tableau. J’en ai déjà vu pour des gros sites marchands.
Oui, voir le lien dans l’article pour les extraits structurés de 2014. Mais, jusqu’à présent, je n’avais vu cela que pour Wikipedia ?