
![]()
Une infographie regroupant les conclusions de la dernière étude 'Ranking Factors' de Semrush, visant à décortiquer l'algorithme de pertinence du moteur de recherche leader. Avec quelques surprises à la clé...
Notre infographie du vendredi est proposée aujourd'hui par l'outil SemRush et nous propose un résumé de sa désormais traditionnelle étude "Ranking Factors" qui tente d'analyser les critères de pertinence de l'algorithme de Google. Malgré une méthodologie différente de celle dévoilée en juin dernier, les résultats sont quasi identiques et laisseront certainement perplexes de nombreux référenceurs, même s'il est toujours - par essence même - difficile d'accorder une confiance sans faille à ce type d'étude. Mais cela peut cependant amener quelques réflexions essentielles et, pourquoi pas, des remises en question de notre métier. Voici en tous cas ces résultats, à chacun de se faire une idée sur leur portée et leur cohérence et d'en répercuter (ou pas) les conclusions dans notre travail au quotidien (cliquez sur l'image pour en obtenir une version agrandie) :
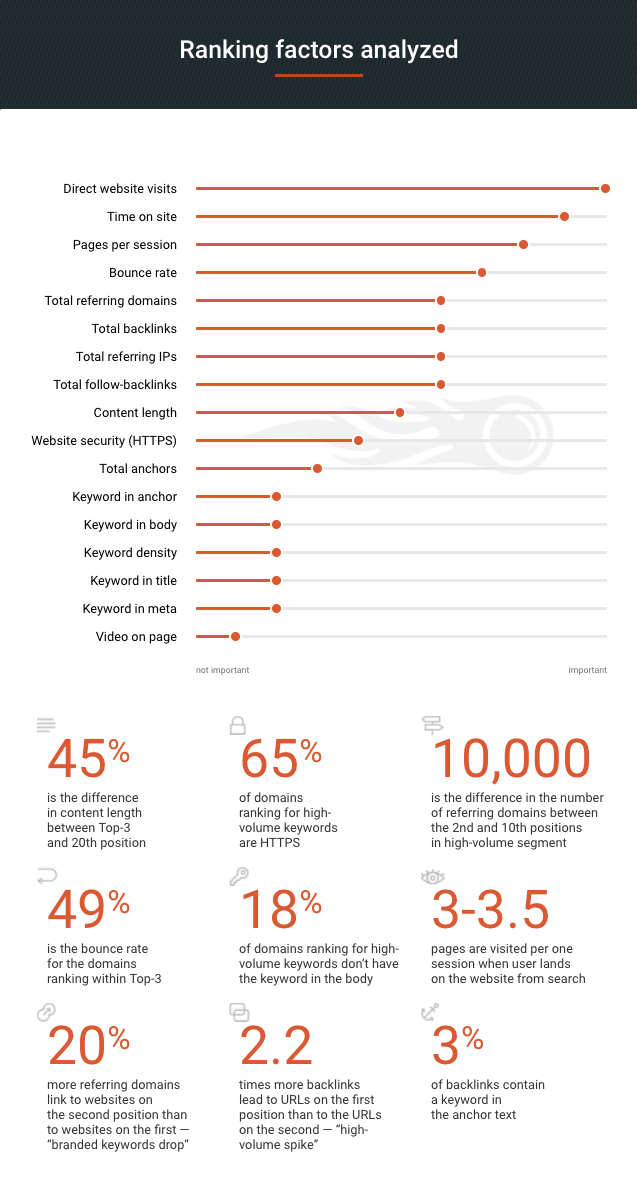 Infographie : Etude Ranking Factors Semrush. Source de l'image : Ranking Factors. |
Articles complémentaires :

Semrush rachète Search Engine Land !

7 documents confidentiels sur le ranking révélés par Google !





 Participez à notre 1ère étude sur le netlinking & les relations presse
Participez à notre 1ère étude sur le netlinking & les relations presse
 À gagner : 3 abonnements d’un an à Réacteur.com
À gagner : 3 abonnements d’un an à Réacteur.com
 Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Quelques minutes suffisent. Un grand merci par avance à tous les participants !
Je vous rejoins, la pondération des critères, telle qu’elle est présentée, est clairement un biais introduit par la méthodologie. Il ne faut probablement pas lire ce graphique comme une représentation de l’algorithme de Google. Ou alors les résultats ne pourraient pas être aussi pertinents à mon avis.
Qu’en est-il par exemple de l’autorité de l’auteur, ou de l’historique des recherches de l’internaute, ou encore de sa position géographique au moment de sa requête ?
Par-contre, l’étude a le mérite de rappeler la façon dont l’expérience utilisateur renseigne Google sur la pertinence d’un site et d’un contenu.
Un site recevant de nombreuses visites directes doit nécessairement apporter quelque-chose d’utile à ses visiteurs fidèles. Cela signifie aussi probablement que sa marque a une certaine notoriété.
De même, si ses visiteurs provenant d’un clic dans les résultats de Google regardent plusieurs pages, et restent longtemps sur le site, c’est que le résultat était pertinent pour eux et que leur expérience utilisateur a été concluante.
Il est donc cohérent qu’au-delà du profil de liens et d’une analyse sémantique du contenu, Google prenne en compte le comportement des humains pour affiner son classement.
Je nuancerais en ajoutant que probablement Google pondère (ou essaie de pondérer) ces indicateurs en fonction des niches et secteurs d’activités. Ce qu’il considère comme un taux de rebond ou un temps passé correct est probablement différent pour un site de petites annonces immobilières, un blog sur la cuisine, et un site d’actus.
Le tout étant qu’il ne se trompe de catégorie pour votre site !
Qu’en pensez-vous ?
Moi j’ai pu constater avec des sites différents que j’ai créé sur la même thématique sur le même secteur local
Ceux qui ont la plus grande notoriété physique ont plus de visites directes sont mieux référencés
Encore un bon exemple de différences entre corrélation et causalité 🙂
Après, sceptique ou pas sur le taux d’engagement comme ranking factor, ce sont des éléments qui sont intéressants d’optimiser, pas seulement pour le SEO, mais aussi pour mieux convertir.
Ce ne serait pas non plus étonnant que Google encourage à soigner son expérience utilisateur comme c’est plus ou moins le cas sur Mobile.
Ravi de voir des échanges entre 3 SEO rock stars dans les commentaires en tout cas ^^
C’est la faute de Moz qui a lancé ce genre d’étude intitulée Ranking Factors, alors que ce sont des observations de conséquence des ranking factors.
C’est comme si tu vois couler une eau verte à la sortie d’un tuyau. Tu ne sais pas s’il y a un pot de peinture verte au robinet ou plusieurs couleurs qui se mélangent.
L’intérêt de cette étude réside dans la méthodologie, qui est un peu moins idiote que les précédentes.
Maintenant, il ne faut pas le prendre comme un mode d’emploi, mais pour ce que c’est et rien de plus. SEMrush eux mêmes écrivent cela noir sur blanc dans leur méthodologie, mais les SEO cherchent toujours le mode d’emploi tout prêt, sans chercher à comprendre plus loin que le bout de leur nez.
Voir mon décryptage de l’étude où je parle de tout ça http://www.laurentbourrelly.com/blog/54624.php
En même temps, « Ranking Factors », ça dit bien ce que ça veut dire, non ? Dans ce cas, il faut utiliser une autre dénomination… Moz ou pas 😉
SERP Symptoms Analysis ça fait moins vendeur ^^
Moi, je trouve que ça claque sa mère plutôt bien 😀
Mais concrètement tu en penses quoi Olivier ? je n’ai pas bien compris ton avis
pour ma part je suis très sceptique sur le fait que le trafic direct soit le 1er des ranking factors.
je l’explique sur http://forum.webrankinfo.com/trafic-direct-1er-des-ranking-factors-etude-semrush-novembre-2017-t192358.html
Je suis très (très très) sceptique aussi… Mais bon, je me remets en question chaque matin, donc je me dis que c’est peut-être un point sur lequel il faut que je me penche un peu plus à l’avenir… Parce que c’est potentiellement possible que Google regarde ça de plus près aujourd’hui… Mais bon, ça bouscule clairement mes certitudes 🙂